
Freestyle Handwritten
Collect / Source thousands of high-quality handwritten datasets in hundreds of languages and dialects to train machine learning (ML) and deep learning (DL) models. We can also help in extracting text within an image.

Receipt/Invoice
Datasets consisting of invoice/receipt where several items were purchased collected from different region & in different languages as required for the ML model. Save significant time & money by transcribing key data from invoices & receipts effectively.

Multilingual Document
Multilingual handwritten data collection services for pattern recognition, computer vision, and other machine learning solutions to train Optical Character Recognition models.
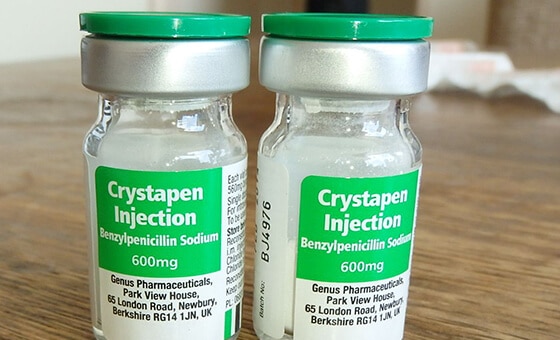
Scene Data Collection
Medicine bottle with labels, English Street/Road scene with car license plate, English Street/Road scene with instruction/info board etc.

- Use Case: Object Recognition Model
- Format: Videos
- Volume: 5,000+
- Annotation: No

- Use Case: Doc. Recognition Model
- Format: Images
- Volume: 15,900+
- Annotation: No

- Use Case: Invoice Recog. Model
- Format: Images
- Volume: 45,000+
- Annotation: No

- Use Case: No. Plate Recognition
- Format: Images
- Volume: 3,500+
- Annotation: No

- Use Case: OCR Model
- Format: Images
- Volume: 90,000+
- Annotation: Yes

- Use Case: Multilingual OCR Model
- Format: Images
- Volume: 23,500+
- Annotation: Yes

- Use Case: Object detection model
- Format: Images
- Volume: 11,500+
- Annotation: No

- Use Case: Receipt AI Models
- Format: Images
- Volume: 75,000+
- Annotation: No






