





Receipt Data Collection
We help you collect various types of invoices like internet invoices, shopping invoices, cab receipts, hotel bills, etc from all across the globe & in languages as required.

Ticket Dataset Collection
We help you source various types of tickets i.e. airline tickets, railway tickets, bus tickets, cruise tickets, etc. from across the globe based on your custom specifications.

EHR Data & Physician Dictation Transcripts
We can offer you off-the-shelf EHR data & Physician Dictation Transcripts from various medical specialties i.e., Radiology, Oncology, Pathology, etc.

Document Dataset Collection
We can help you collect all types of important documents - like driving licenses, credit cards, from different geographies & languages as required to train ML models.


Monologue Speech Collection
Collect scripted, guided or spontaneous speech dataset from individual speaker. The speaker is selected based on your custom requirement i.e. Age, Gender, Ethnicity, Dialect, Language etc.

Dialogue Speech Collection
Collect guided or spontaneous speech datasets / interaction between a Call Centre Agent & Caller or Caller & Bot based on custom requirement or as specified in the project.

Acoustic Data Collection
We can professionally record studio-quality audio data be it restaurants, offices, or homes or from various environments and languages, through our global network of collaborators.

Natural Language Utterance Collection
Shaip has a rich experience in collecting diverse natural language utterances to train audio-based ML systems with speech samples in 100+ languages & dialects from local and remote speakers.


Document Dataset Collection
We provide image data sets of various documents i.e., driving license, identity card, credit card, invoice, receipt, menu, passport, etc.

Facial Dataset Collection
We offer a variety of facial image datasets consisting of facial features, & expressions, collected from people from multiple ethnicities, age, gender, etc.

Healthcare Data Collection
We provide medical images i.e., CT Scan, MRI, Ultrasound, X-ray from various medical specialties such as Radiology, Oncology, Pathology, etc.
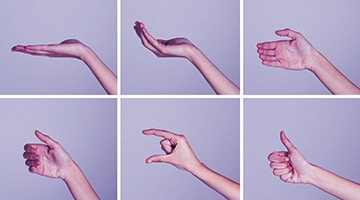
Hand Gesture Data Collection
We offer image data sets of various hand gestures from people across the globe, from multiple ethnicities, age groups, gender, etc.


Human Posture Video Dataset Collection
We offer video datasets of various human postures like walking, sitting, sleeping, etc. under different lighting conditions & different age groups.

Drones & Aerial Video Dataset Collection
We offer video data with an aerial view using drones for different instances like traffic, stadium, crowd, etc.

CCTV/Surveillance Video Dataset
We can collect surveillance video from security cameras for law enforcement to train and identify a person having criminal background.

Traffic Video Dataset Collection
We can collect traffic data from multiple locations under different lighting conditions and intensity to train your ML models.

On-Site Data Collection Services
Need data collected at your desired location? We offer tailored on-site data collection services, with customized crowd-sourcing solutions that fit your specific requirements.
- Biometric Data Gathering at Location
- Field-Based Speech Data Collection
- On-Site Annotation and Labeling Projects

Crowd-Sourced Data Collection
Looking for diverse, large-scale datasets? Our global crowd-sourcing network provides fast, scalable, and diverse data collection solutions, ideal for projects that require wide-ranging inputs.
- Voice Command and Wake Word Recordings
- Object and Product Image Capture
- Human Activity Video Recording

Device-Specific Data Collection
Need data tailored to your unique technology? We specialize in collecting data from specific devices to ensure accurate and relevant inputs for your AI and machine learning needs.
- Image Capture from Specific Mobile Devices
- Video Data Collection Using Custom Cameras

Environment-Specific Data Collection
Need data from controlled or unique environments? We gather contextually rich datasets from specific settings to meet your specialized requirements.
- Studio-Based Speech Recording
- Voice Data Collection in Noisy Environments
- In-Vehicle Video Data Gathering

Technology

Healthcare

Retail

Automotive

Financial Services

Government
The data collection process is a foundational element in the development of artificial intelligence (AI) and machine learning (ML) solutions. It begins with identifying and sourcing relevant data through two primary approaches: custom data collection and existing data sources. Custom collection involves the use of freelancers, crowdsourcing, in-house teams, and field collectors to gather data tailored to specific project requirements. On the other hand, existing data can be obtained from internal databases, external data repositories, social media platforms, and through web scraping of publicly available content. In some cases, organizations may also utilize AI-generated synthetic data to augment and diversify real-world datasets.
A critical aspect of this process is ensuring data accuracy from the outset, as the quality of collected data directly influences the effectiveness of AI models. Once data is gathered, it undergoes data preprocessing—a series of steps that include cleaning, transforming, and organizing raw data. This stage is essential for removing noise, addressing missing values, and standardizing data formats, making the information suitable for analysis by AI algorithms.

