
The future of artificial intelligence isn’t limited to understanding just text or images alone—it’s about creating systems that can process and integrate multiple types of data simultaneously, just like humans do. Multimodal AI represents this transformative leap forward, enabling machines to analyze text, images, audio, and video together to deliver unprecedented insights and capabilities.
As businesses race to implement more sophisticated AI solutions, the multimodal AI market is experiencing explosive growth, projected to expand from $1.2 billion in 2023 to over $15 billion by 2032. This surge reflects a fundamental shift in how organizations approach AI implementation, moving beyond single-modality systems to embrace the rich, contextual understanding that multimodal AI provides.
Understanding Multimodal AI: Beyond Single-Mode Intelligence

Multimodal AI refers to artificial intelligence systems that can process, understand, and generate insights from multiple types of data inputs simultaneously. Unlike traditional unimodal AI that might only analyze text or images, multimodal systems integrate diverse data streams—combining visual, auditory, and textual information to create a more comprehensive understanding of complex scenarios.
“The real power of multimodal AI lies in its ability to mirror human perception, “When we interact with the world, we don’t just see or hear—we combine all our senses to understand context and make decisions. Multimodal AI brings us closer to that natural intelligence.”
The Evolution from Unimodal to Multimodal Systems
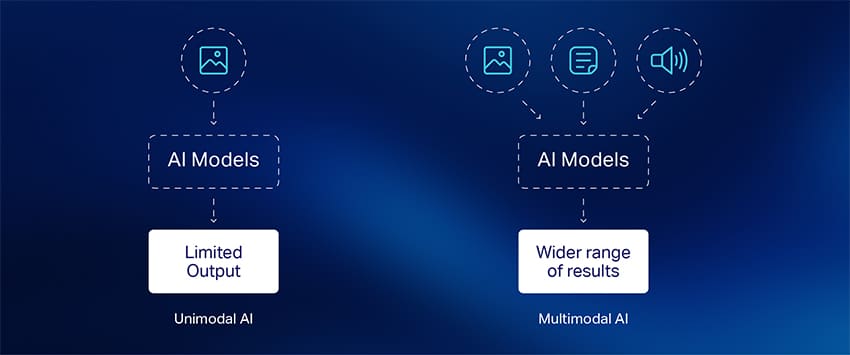
The journey from single-mode to multimodal AI represents a significant technological advancement. Early AI systems were highly specialized—image classifiers could identify objects but couldn’t understand associated text descriptions, while natural language processors could analyze sentiment but missed visual cues that provided crucial context.
This limitation became increasingly apparent in real-world applications. A customer service chatbot analyzing only text might miss the frustration evident in a customer’s voice tone, while a security system relying solely on video feeds could overlook audio cues indicating potential threats.
How Multimodal AI Works: Architecture and Integration
Understanding the technical foundation of multimodal AI helps businesses appreciate both its potential and implementation requirements. At its core, a multimodal AI system consists of three primary components working in harmony to process diverse data types.
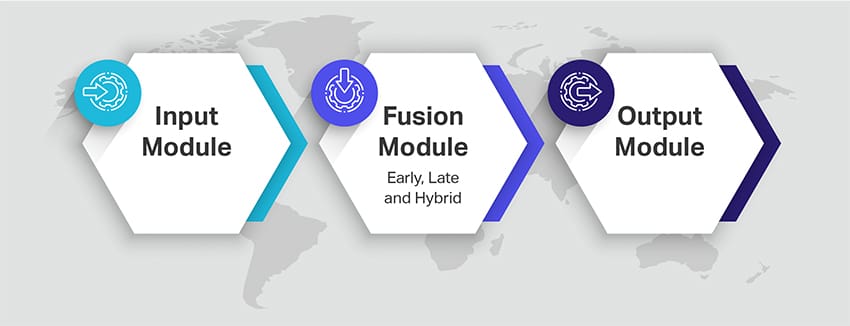
Input Module: The Data Gateway
The input module serves as the entry point for different data modalities. Each type of data—whether text, image, audio, or video—requires specialized neural networks designed to extract relevant features. For businesses collecting multimodal training data, this means ensuring data quality across all input types from the start.
These specialized networks act as e xpert translators, converting raw data into mathematical representations that the AI system can process. A speech recognition network might extract phonetic patterns and emotional indicators from audio, while a computer vision network identifies objects, faces, and spatial relationships in images.
Fusion Module: Where Magic Happens
The fusion module represents the breakthrough innovation in multimodal AI. This component combines and aligns data from different modalities, creating a unified understanding that transcends individual data types. Research from MIT’s Computer Science and AI Laboratory demonstrates that effective fusion strategies can improve AI accuracy by up to 40% compared to single-modality approaches.
Three primary fusion strategies dominate current implementations:
Early Fusion: Combines raw data from different modalities at the input level, allowing the model to learn cross-modal relationships from the ground up.
Late Fusion: Processes each modality independently before combining the results, offering more flexibility but potentially missing subtle inter-modal connections.
Hybrid Fusion: Leverages both approaches, processing some modalities together while keeping others separate until later stages.
Output Module: Delivering Actionable Insights
The output module translates the fused understanding into practical applications—whether generating responses, making predictions, or triggering actions. This flexibility enables multimodal AI to support diverse business needs, from automated content generation to complex decision-making processes.
[Also Read: What is Multimodal Data Labeling? Complete Guide 2025]
Transformative Business Applications of Multimodal AI
The practical applications of multimodal AI span virtually every industry, with early adopters already reporting significant operational improvements and competitive advantages.
Healthcare: Revolutionizing Diagnosis and Treatment

For organizations developing healthcare AI solutions, the ability to process diverse medical data types simultaneously opens new possibilities for personalized treatment plans and predictive health monitoring.
Customer Experience: Creating Truly Intelligent Interactions

“We’ve seen customer satisfaction scores increase by 35% after implementing multimodal analysis in our contact centers,” shares Maria Rodriguez, VP of Customer Experience at a Fortune 500 retailer. The system picks up on frustration in a customer’s voice and automatically adjusts its approach, even escalating to human agents when emotional indicators suggest it’s necessary.”
Retail and E-commerce: Personalizing the Shopping Journey

This capability requires sophisticated data annotation services to ensure AI models accurately understand the relationships between visual elements and textual descriptions.
Manufacturing and Quality Control

Security and Surveillance

- Transcribing spoken dialogue
- Identifying visual elements and actions
- Marking temporal relationships between audio and visual events
- Labeling emotional contexts and non-verbal communications
This complexity underscores the importance of working with experienced annotation teams who understand multimodal relationships and can maintain consistency across diverse data types.

Best Practices for Multimodal AI Implementation
Successfully implementing multimodal AI requires careful planning and execution. Based on insights from industry leaders and recent deployments, several best practices have emerged.

Start with Clear Use Case Definition
“The biggest mistake we see is organizations trying to implement multimodal AI without clearly defining what problems they’re solving,” notes Dr. James Liu, Chief AI Officer at a leading technology consultancy. “Start with specific use cases where multimodal understanding provides clear value over single-modality approaches.”
Invest in Data Infrastructure
Multimodal AI demands robust data infrastructure capable of handling diverse data types at scale. This includes:
- Storage systems optimized for different file types and sizes
- Processing pipelines that maintain synchronization across modalities
- Version control systems that track relationships between paired data
- Quality assurance workflows that validate cross-modal consistency
Embrace Iterative Development
Rather than attempting to build comprehensive multimodal systems from scratch, successful implementations often start with two modalities and gradually expand. A retail company might begin by combining product images with descriptions, then later add customer review sentiment and behavioral data.
Prioritize Explainability
As multimodal AI systems become more complex, understanding their decision-making processes becomes crucial. Implementing explainability features helps build trust with stakeholders and enables continuous improvement of the models.

The Future of Multimodal AI: Trends and Predictions
As we look toward the future, several trends are shaping the evolution of multimodal AI technology and its business applications.
Integration with Generative AI
The convergence of multimodal understanding with generative AI capabilities promises unprecedented creative and analytical possibilities. Systems that can understand multiple input types and generate multimodal outputs will enable entirely new categories of applications, from automated content creation to immersive virtual experiences.
Edge Deployment and Real-Time Processing
Advances in edge computing and model optimization are making it possible to deploy multimodal AI directly on devices. This trend will enable real-time applications in autonomous vehicles, augmented reality, and IoT devices without relying on cloud connectivity.
Standardization and Interoperability
As multimodal AI matures, we’re seeing efforts to standardize data formats, annotation schemas, and model architectures. These standards will facilitate easier data sharing, model transfer, and collaborative development across organizations.
Ethical AI and Regulation
Growing awareness of AI’s societal impact is driving the development of ethical guidelines and regulations specifically addressing multimodal systems. Organizations must prepare for compliance requirements around data privacy, algorithmic transparency, and fair representation across all modalities.

Getting Started with Multimodal AI
For organizations ready to embrace multimodal AI, success depends on strategic planning and access to quality resources. Here’s a practical roadmap:
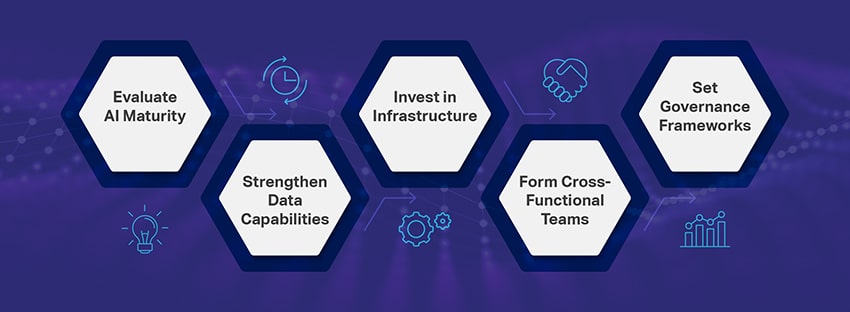
1. Assess Your Current AI Maturity
Evaluate existing AI capabilities and identify areas where multimodal understanding could provide significant value. Consider starting with pilot projects that combine just two modalities before scaling to more complex implementations.
2. Build or Partner for Data Capabilities
Determine whether to build internal data collection and annotation capabilities or partner with specialized providers. Given the complexity of multimodal data, many organizations find that leveraging comprehensive data catalogs accelerates development while ensuring quality.
3. Invest in the Right Infrastructure
Ensure your technical infrastructure can support multimodal AI requirements, including:
- Scalable storage for diverse data types
- Processing power for model training and inference
- Tools for data versioning and experiment tracking
4. Develop Cross-Functional Teams
Successful multimodal AI projects require collaboration between data scientists, domain experts, and business stakeholders. Create teams that understand both technical requirements and business objectives.
5. Establish Governance Frameworks
Implement clear policies for data usage, model governance, and ethical considerations. This foundation becomes increasingly important as multimodal AI systems influence critical business decisions.
Real-World Success Stories
The transformative impact of multimodal AI is best illustrated through real-world implementations that have delivered measurable business value.
Case Study: Enhancing Patient Care Through Multimodal Analysis

- 45% reduction in missed critical events
- 30% improvement in early intervention rates
- 25% decrease in average ICU length of stay
“The multimodal system catches subtle changes that individual monitoring systems miss,” Chief Medical Officer. “It’s like having an expert clinician watching every patient 24/7, noticing patterns across all available data.”
Case Study: Revolutionizing Retail Customer Experience

- Upload photos of desired styles
- Describe modifications in natural language
- Receive personalized recommendations based on visual and textual preferences
Results after six months:
- 52% increase in customer engagement
- 38% improvement in conversion rates
- 41% reduction in product returns
Case Study: Transforming Financial Services with Multimodal Authentication

- 78% reduction in fraud attempts
- 90% decrease in false rejection rates
- 60% improvement in customer authentication time