-
-
Company

For quite some time, there has been deliberation on how Artificial Intelligence (AI) is set to change every aspect of human lives, and by now you must have already realized that it has the potential to be the most disruptive technology ever. Today we can talk to Siri, Cortana, or Google to get our basic queries addressed, but much of their actual potential is yet unknown.
Building AI that genuinely understands human language requires more than raw data — it demands precision-labeled, linguistically expert training datasets delivered at enterprise scale. Shaip is a leading NLP service provider offering end-to-end natural language processing services and solutions for AI teams worldwide: from custom text and audio data collection to expert annotation, off-the-shelf NLP datasets, and fully managed workforce delivery across 150+ languages.
Whether you’re training a conversational AI system, fine-tuning a large language model (LLM), building a sentiment analysis engine, or scaling a named entity recognition (NER) pipeline — Shaip’s 30K+ credentialed collaborators deliver the structured, high-quality NLP training data your models need to perform accurately in the real world. Trusted by Fortune 500 companies across healthcare, finance, technology, and retail, Shaip’s NLP solutions combine proprietary platform tooling, 6 Sigma quality processes, and domain-experts to meet the accuracy and throughput demands of production-grade AI.

Every high-performing language model begins with purpose-built, domain-specific training data. Shaip’s NLP data collection services source the precise input your model needs — at volume, in your language, and with the linguistic variability that real-world deployment demands.
We source large-volume, customized text corpora across formats: emails, customer reviews, social media posts, support tickets, legal contracts, financial documents, and more. Available in 150+ languages and regional dialects, our text collection services power chatbot training, LLM fine-tuning, search relevance systems, and document understanding pipelines.
From scripted prompts to spontaneous conversational dialogue, Shaip collects high-quality audio recordings tailored to your ASR or voice AI requirements — including specific accents, noise environments, speaker demographics, and channel conditions. Delivered as standalone collections or as complete ASR bundles with transcription, pronunciation lexicons, and language-specific documentation for immediate model training. All collected data is delivered with full metadata, speaker attribution, and quality verification through Shaip’s proprietary annotation platform.
Accurate NLP models demand accurately annotated training data. Shaip’s data annotation services combine a credentialed multilingual workforce with a proprietary platform to deliver consistently precise labels at enterprise scale — with built-in quality gates and transparent delivery tracking.

Our NLP annotation capabilities cover every major task type:
All annotation delivered through a 6 Sigma stage-gate quality process with inter-annotator agreement scoring and continuous feedback loops.

Browse through our audio dataset of diverse off-the-shelf NLP datasets, comprising of over 20,000 hours of audio, on a variety of topics such as Call-center, General Conversation, Debates, Speeches, Talks, Documentary, Events, General Conversation, Movie, News etc., in over 40 languages.
We offer a skilled resource that becomes an extension of your team to support your data annotation tasks, through tools that you prefer while maintaining the desired quality. Our experienced workforce understand the subtleties in human languages and apply the best practices learned by labeling millions of audio & text documents to deliver world-class data labeling solution for natural language processing.

From text/audio collection to annotation, we bring a greater understanding of the spoken world with detailed, accurately labeled text and audio to improve the performance of your NLP models. Whether you’re training a virtual/digital assistant, want to review legal contract, or build financial analysis algorithm, we provide the gold-standard data you need to make your models work in the real world. Our team understands the language, dialect, syntax, & sentence structure to accurately tag text, based on your business requirement.
We are one of the very few NLP companies that takes pride in their strong linguistic ability. We have global workforce of over 30,000 collaborators from across the globe, having expertise in over 150 languages. We’ve helped early-stage startups, small & medium enterprises, and worked with top fortune 500 companies across different verticals i.e., healthcare, retail/e-commerce, finance, technology, and more to achieve their NLP project goals.




Over 50k hours of off-the-shelf audio/speech datasets to get you going.

Analyze human emotion by interpreting nuances in client reviews, social media, etc.

Collect text datasets i.e., emails, SMS, blogs, documents, research papers etc.


Training digital assistants require a large set of quality data from different geographies, languages, dialects, set-ups, and formats. At Shaip, we offer training data for AI Models with Human-in-the-loop who have the required knowledge, domain expertise, and are well aware of the specific needs of the client.
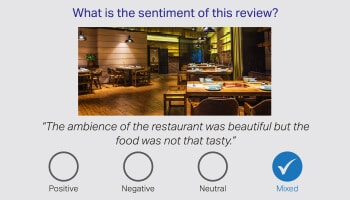
It is rightly said, that words alone fail to communicate the whole story, and the onus lies on human annotators to interpret the ambiguity in human language. Hence identifying the Sentiment of a customer, based on the conversation is of utmost importance. Our language experts from various domains can interpret nuances in product reviews, financial news, and social media.

Named Entity Recognition (NER) is identifying, extracting, and classifying the named entities within a text, into pre-defined categories. The text could be categorized as a place, name, organization, product, quantity, value, percentage, etc. With NER you can address real-world questions such as which organizations were mentioned in the article etc.
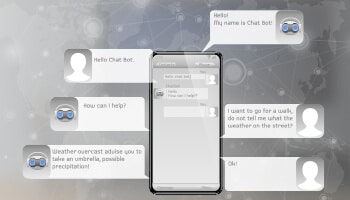
Robust, well-trained Virtual Chatbots or Digital Assistants have revolutionized the way customers communicate with the sellers adding to significant improvement in customer experience.

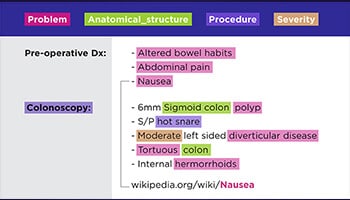
From doctors’ handwritten prescriptions to conference calls notes, our specialists can digitize any form of data i.e., archived documents, legal contracts, patientt health records, etc.

Categorization also known as classification or tagging is the process of classifying text into organized groups and labeling it, based on its features of interest.

Human evaluation and post-editing of machine translation output to measure fluency, adequacy, and domain accuracy — enabling reliable MT systems for multilingual deployments.
Curated instruction-following datasets, prompt-response pairs, and RLHF preference data to fine-tune and align large language models to your domain, tone, and task requirements.
Annotation of complex document structures — contracts, medical records, financial filings — to train document AI models that extract, classify, and reason over unstructured text at scale.

Topic Analysis or topic labeling is identifying and extracting meaning from a given text by identifying recurrent topics/themes under consideration.

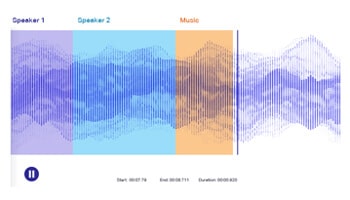
Transcribe speech/podcast/seminar,call conversation into text. Leverage humans to accurately annotate audio/speech files to train NLP models accurately.

Categorize sounds or utterances to classify speech/audio based on language, dialect, semantics, lexicons, etc.
Our pool of experts who are proficient in text/audio annotation/ labeling can procure accurate & effectively annotated NLP datasets.
Our team helps you prepare text/audio data for training AI engines, saving valuable time & resources.
Our team of collaborators can accommodate additional volume while maintaining the quality of data output for your NLP Solutions.
As experts in training and managing teams, we ensure projects are delivered within the defined budget.
The team analyzes data from multiple sources & is capable of producing AI-training data efficiently and in volumes across all industries.
The wide gamut of audio/text data provides AI with copious amounts of information needed to train faster.

Dedicated and trained teams:

Highest process efficiency is assured with:

The patented platform offers benefits:

AI chatbots provide enhanced user experience by learning from previous interactions, understanding user behavior & comprehending different languages using advanced decision-making skills.

Automatic speech recognition (ASR) has come a long way. Though it was invented long ago, it was hardly ever used by anyone. However, time and technology have now changed significantly.

The global natural language processing market is slated to increase from $1.8 billion in 2021 to $4.3 billion in 2026, growing at a CAGR of 19.0% during the period.
Empowering teams to build world-leading AI products.
NLP is a branch of artificial intelligence that enables machines to understand, analyze, and respond to human language, both text and speech, by interpreting context, sentiment, and intent.
NLP involves processing human language using algorithms that analyze grammar, syntax, semantics, and context. It relies on large volumes of annotated data to train AI models to extract meaning, identify patterns, and generate accurate responses.
NLP is used in applications like virtual assistants, chatbots, sentiment analysis, machine translation, text summarization, spam detection, and grammar correction. It powers systems that make human-computer interactions more efficient and natural.
NLP services include text collection (sourcing diverse text data), audio collection (recording speech data), data annotation (labeling text and audio for training AI), and transcription (converting speech into text for analysis).
NLP solutions enhance AI models by providing accurately labeled datasets that help the models understand human language better. This improves tasks like sentiment analysis, named entity recognition (NER), conversational AI, and chatbot training.
Key industries include healthcare (analyzing medical records and patient sentiment), finance (fraud detection and document analysis), and e-commerce (personalized recommendations and customer support automation).
Timelines vary based on the project’s size and complexity but are optimized to deliver high-quality data efficiently.
Quality is guaranteed through rigorous validation processes, expert annotators, and advanced tools, ensuring the data meets the highest standards.
Costs depend on factors like project scope, data complexity, and customization needs. Contact Shaip for a personalized quote based on your requirements.
NLP as a service refers to a fully managed data delivery model where an NLP service provider handles every stage of your language data pipeline — collection, annotation, quality assurance, and delivery — on your behalf. Shaip offers project-based, subscription, and embedded team delivery models to fit different organizational needs and project scales.
Each language pool consists of native or near-native speakers recruited and screened for domain knowledge. Annotations are calibrated against gold-standard reference sets, and a 6 Sigma stage-gate quality process with inter-annotator agreement scoring ensures consistency across all language pairs and dialects.
Shaip operates HIPAA-aware workflows for healthcare NLP projects and aligns with GDPR consent management requirements for EU data collection. All projects include audit-trail documentation, data provenance records, and role-based access controls for enterprise compliance teams.
Yes. Shaip delivers instruction-following datasets, prompt-response pairs, and RLHF preference data for LLM fine-tuning and alignment. Our Generative AI solutions page covers the full scope of LLM training data services.
Data collection involves sourcing raw text or audio — the input material your model will learn from. Annotation involves labeling that raw data with structured tags, categories, entities, or sentiment indicators that tell the model what to understand. Shaip offers both as standalone services or as an integrated end-to-end NLP data solution.
Yes. Shaip has worked with early-stage startups, SMEs, and Fortune 500 enterprises. We offer flexible project scoping, minimum viable dataset packages for MVP-stage AI, and scalable delivery models that grow with your annotation requirements. Contact us for a custom quote.
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Manage your cookie preferences below:
Essential cookies enable basic functions and are necessary for the proper function of the website.
Google Tag Manager simplifies the management of marketing tags on your website without code changes.
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Service URL: policies.google.com (opens in a new window)
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
Google Ads is an online advertising platform that enables businesses to create targeted ads displayed on Google search results and partner sites.
Service URL: policies.google.com (opens in a new window)
You can find more information in our Cookie Policy and Privacy Policy.