- What We Do
-
-
-
Speciality
-
-
-
- Off-the-shelf Data
-
- Solutions
- Platform
- Company
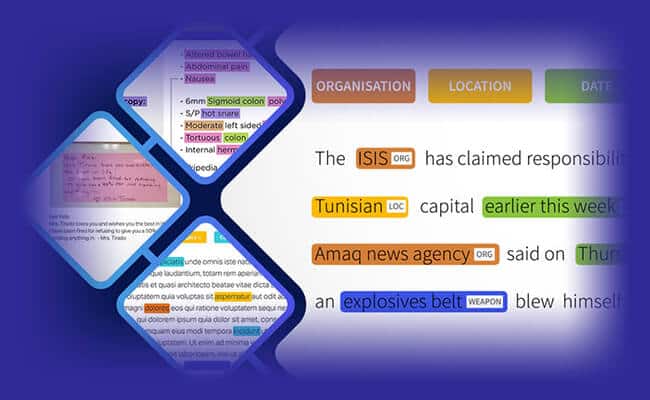




This is perhaps the most simple and fundamental NER approach. It will use a dictionary with many words, synonyms, and vocabulary collection. The system will check whether a particular entity present in the text is also available in the vocabulary. By using a string-matching algorithm, a cross-checking of entities is performed. There is a need for constantly upgrading the vocabulary dataset for the effective functioning of NER model.

Rule based methods rely on predefined rules to identify entities in text. These systems use a set of pre-set rules, which are
Pattern-based rules – As the name suggests, a pattern-based rule follows a morphological pattern or string of words used in the doc.
Context-based rules – Context-based rules depend on the meaning or the context of the word in the document.

In Machine learning-based systems, statistical modeling is used to detect entities. A feature-based representation of the text document is used in this approach. You can overcome several drawbacks of the first two approaches since the model can recognize entity types despite slight variations in their spellings for deep learning. Additionally, you can train a custom model for domain-specific NER, and it is important to fine-tune the model to improve accuracy and adapt to new data.

Phase 1: Technical domain expertise (Understanding project scope & annotation guidelines)

Phase 2: Training appropriate resources for the project

Phase 3: Feedback cycle and QA of the annotated documents


1.2 Insurance Domain
It involves extraction of entities in insurance documents such as


It identifies a discrete noun phrase in a text. A noun phrase may be either simple (e.g. single head word like noun, proper noun or pronoun) or complex (e.g. a noun phrase that has a head word along with its associated modifiers)

PII refers to Personally Identifiable Information. This task involves annotation of any key identifiers which can relate back to a person’s identity.

PHI refers to Protected Health Information. This task involves annotation of 18 key patient identifiers as identified under HIPAA, in order to de-identify a patient record/identity.

5.1. Entity Identification (e.g. Person, place, organization, etc.

5.2. Identification of word denoting the main incident (i.e. trigger word)

5.3. Identification of relation between a trigger and entity types



