")
Every time we hear a word or read a text, we have the natural ability to identify and categorize the word into people, place, location, values, and more. Humans can quickly recognize a word, categorize it and understand the context. For example, when you hear the word ‘Steve Jobs,’ you can immediately think of at least three to four attributes and segregate the entity into categories.
- Person: Steve Jobs
- Company: Apple
- Location: California
Since computers don’t have this natural ability, they require our help to identify words or text and categorize them. Computers must process raw text to extract meaningful information, as they face the challenge of transforming unstructured, authentic textual data into structured knowledge. It is where Named Entity Recognition(NER) comes into play.
Let’s get a brief understanding of NER and its relation to NLP.
What is Named Entity Recognition (NER)?
Named Entity Recognition is a part of Natural Language Processing. The primary objective of NER is to process structured and unstructured data and classify these named entities into predefined categories. Some common categories include name, location, company, time, monetary values, events, and more.
In a nutshell, NER deals with:
- Named entity recognition/detection – Identifying a word or series of words in a document.
- Named entity classification – Classifying every detected entity into predefined categories.
But how is NER related to NLP?
Natural Language processing helps develop intelligent machines capable of extracting meaning from speech and text. Machine Learning helps these intelligent systems continue learning by training on large amounts of natural language datasets.
Generally, NLP consists of three major categories:
- Understanding the structure and rules of the language – Syntax
- Deriving meaning of words, text, and speech and identifying their relationships – Semantics
- Identifying and recognizing spoken words and transforming them into text – Speech
NER helps in the semantic part of NLP, extracting the meaning of words, identifying and locating them based on their relationships.
A Deep Dive into Common NER Entity Types
Named Entity Recognition models categorize entities into various predefined types. Understanding these types is crucial for leveraging NER effectively. Here’s a closer look at some of the most common ones:
- Person (PER): Identifies individuals’ names, including first, middle, and last names, titles, and honorifics. Example: Nelson Mandela, Dr. Jane Doe
- Organization (ORG): Recognizes companies, institutions, government agencies, and other organized groups. Example: Google, World Health Organization, United Nations
- Location (LOC): Detects geographical locations, including countries, cities, states, addresses, and landmarks. Example: London, Mount Everest, Times Square
- Date (DATE): Extracts dates in various formats. Example: January 1, 2024, 2024-01-01
- Time (TIME): Identifies time expressions. Example: 3:00 PM, 15:00
- Quantity (QUANTITY): Recognizes numerical quantities and units of measurement. Example: 10 kilograms, 2 liters
- Percentage (PERCENT): Detects percentages. Example: 50%, 0.5
- Money (MONEY): Extracts monetary values and currencies. Example: $100, €50
- Other (MISC): A catch-all category for entities that don’t fit into the other types. Example: Nobel Prize, iPhone 15″
Examples of Named Entity Recognition
Some of the common examples of a predetermined entity categorization are:
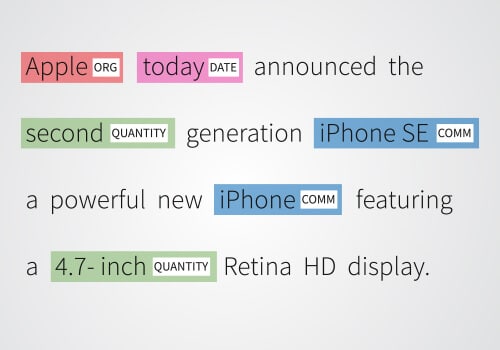
Apple: is labeled as ORG (Organization) and highlighted in red. Today: is labeled as DATE and highlighted in pink. Second: is labeled as QUANTITY and highlighted in green. iPhone SE: is labeled as COMM (Commercial product) and highlighted in blue. 4.7-inch: is labeled as QUANTITY and highlighted in green.
Ambiguity in Named Entity Recognition
The category a term belongs to is intuitively quite clear for human beings. However, that’s not the case with computers – they encounter classification problems. For example:
Manchester City (Organization) won the Premier League Trophy whereas in the following sentence the organization is used differently. Manchester City (Location) was a Textile and industrial Powerhouse.
Your NER model needs training data to conduct accurate entity extraction and classifies named entities based on learned patterns. If you are training your model on Shakespearean English, needless to say, it won’t be able to decipher Instagram. NER models are evaluated by comparing their predictions to the ground truth annotations, which are the correct, manually labeled entities in the dataset.
Different NER Approaches
The primary goal of a NER model is to label entities in text documents and categorize them. The following three approaches are generally used for this purpose. However, you can choose to combine one or more methods as well. The different approaches to creating NER systems are:

Dictionary-based systems
The dictionary-based system is perhaps the most simple and fundamental NER approach. It will use a dictionary with many words, synonyms, and vocabulary collection. The system will check whether a particular entity present in the text is also available in the vocabulary. By using a string-matching algorithm, a cross-checking of entities is performed.
One drawback of using this approach is there is a need for constantly upgrading the vocabulary dataset for the effective functioning of the NER model.
Rule-based systems
In this approach, information is extracted based on a set of pre-set rules. There are two primary sets of rules used,
Pattern-based rules – As the name suggests, a pattern-based rule follows a morphological pattern or string of words used in the document.
Context-based rules – Context-based rules depend on the meaning or the context of the word in the document.
Machine learning-based systems
In Machine learning-based systems, statistical modeling is used to detect entities. A feature-based representation of the text document is used in this approach. You can overcome several drawbacks of the first two approaches since the model can recognize entity types despite slight variations in their spellings.
Deep learning
Deep learning methods for NER leverage the power of neural networks like RNNs and transformers to understand long-term text dependencies. The key benefit of using these methods is they are well-suited for large-scale NER tasks with abundant training data.
Furthermore, they can learn complex patterns and features from the data itself, eliminating the need for manual training. But there’s a catch. These methods require a hefty amount of computational power for training and deployment.
Hybrid Methods
These methods combine approaches like rule-based, statistical, and machine learning to extract named entities. The goal is to combine the strengths of each method while minimising their weaknesses. The best part of using hybrid methods is the flexibility you get by merging multiple techniques by which you can extract entities from diverse data sources.
However, there’s a possibility that these methods may end up getting much more complex than the single-approach methods as when you merge multiple approaches, the workflow may get confusing.
Use Cases for Named Entity Recognition (NER)?
Unveiling the Versatility of Named Entity Recognition (NER).
NER is applied across various domains, from finance to healthcare, demonstrating its adaptability and broad utility.
- Chatbots: Aids chatbots like GPT in understanding user queries by identifying key entities.
- Customer Support: Categorizes feedback by product, accelerating response time.
- Finance: Extracts crucial data from financial reports,for trend analysis and risk assessment.
- Healthcare: Extracting patient data from electronic health records (EHR).
- HR: Streamlines recruitment by summarizing applicant profiles & channeling feedback.
- News Providers: Categorizes content into relevant information, speeding up reporting.
- Recommendation Engines: Companies like Netflix employ NER to personalize recommendations based on user behavior.
- Search Engines: By categorizing web content, NER enhances search result accuracy.
- Sentiment Analysis: Extracts brand mentions from reviews, fueling sentiment analysis tools.
- eCommerce: Enhancing personalized shopping experiences.
- Legal: Analyzing contracts and legal documents.
The entities extracted through NER can be integrated into knowledge graphs, enabling enhanced data organization and retrieval.
Who Uses Named Entity Recognition (NER)?
NER (Named Entity Recognition) being one of the powerful natural language processing (NLP) techniques, has made its way to various industries and domains. Organizations often deploy a named entity recognition system to automate information extraction and improve efficiency. Here are some examples:
- Search engines: NER is a core component of modern-day search engines such as Google and Bing. It is used to identify and categorise entities from web pages and search queries to provide more relevant search results. For example, with the help of NER, the search engine can differentiate between “Apple” the company vs. “apple” the fruit based on context. The implementation of the NER process is crucial for delivering accurate and context-aware results.
- Chatbots: Chatbots and AI assistants can use NER to understand key entities from user queries. By doing so, chatbots can provide more precise responses. For example, if you ask “Find Italian restaurants near Central Park” the chatbot will understand “Italian” as the cuisine type, “restaurants” as the place, and “Central Park” as the location. The NER process enables these systems to extract relevant information efficiently.
- Investigative Journalism: The International Consortium of Investigative Journalists (ICIJ), a renowned media organization used NER to analyse the Panama Papers, a massive leak of 11.5 million financial and legal documents. In this case, NER was used to automatically identify people, organizations, and locations across millions of unstructured documents, uncovering hidden networks of offshore tax evasion.
- Bioinformatics: In the field of Bioinformatics, NER is used to extract key entities such as genes, proteins, drugs, and diseases from biomedical research papers and clinical trial reports. Such data helps in speeding up the process of drug discovery. Pre-training of models on large biomedical corpora can significantly improve the performance of NER systems in this specialized domain.
- Social Media Monitoring: Brands over social media use NER to track the overall metrics of their ad campaigns and how their competitors are doing. For example, there’’s an airline that uses NER to analyse tweets mentioning their brand. It detects negative commentary around entities like “lost luggage” at a particular airport so that they can resolve the problem as fast as possible. The NER process is essential for extracting actionable insights from vast amounts of social media data.
- Contextual Advertising: Advertisement platforms use NER to extract key entities from web pages to display more relevant ads alongside the content, eventually improving ad targeting and click-through rates. For example, if NER detects “Hawaii”, “hotels”, and “beaches” on a travel blog, the ad platform will show deals for Hawaiian resorts rather than generic hotel chains.
- Recruiting and Resume Screening: You can instruct NER to find you the exact required skills and qualifications based on the applicant’s skill set, experience, and background. For example, a recruitment agency can use NER to match candidates automatically. Companies may use their own models tailored to specific requirements, or leverage pre-trained models to enhance the accuracy of their named entity recognition system..
Applications of Named Entity Recognition (NER) Across Industries
NER has several use cases in many fields related to Natural Language Processing and creating training datasets for machine learning and deep learning solutions. A trained model is used to perform NER on new data, enabling automated extraction of entities from large volumes of text. Some of the applications are:
Customer Support
A NER system can easily spot relevant customer complaints, queries, and feedback based on crucial information such as product names, specifications, branch locations, and more. The complaint or feedback is aptly classified and diverted to the correct department by filtering priority keywords.
Efficient Human Resources
NER helps Human Resource teams improve their hiring process and reduce the timelines by quickly summarizing applicants’ resumes. The NER tools can scan the resume and extract relevant information – name, age, address, qualification, college, and so forth.
Additionally, the HR department can also use NER tools to streamline the internal workflows by filtering employee complaints and forwarding them to the concerned departmental heads.
Content Classification
Content classification is a humongous task for news providers. Classifying the content into different categories makes it easier to discover, gain insights, identify trends, and understand the subjects. A Named Entity Recognition tool can come in handy for news providers. It can scan many articles, identify priority keywords, and extract information based on the persons, organization, location, and more.
Optimizing Search Engines

Accurate Content Recommendation
Several modern applications depend on NER tools to deliver an optimized and customized customer experience. For example, Netflix provides personalized recommendations based on user’s search and view history using named entity recognition.

Named Entity Recognition makes your machine learning models more efficient and reliable. However, you need quality training datasets for your models to work at their optimum level and achieve intended goals. All you need is an experienced service partner who can provide you with quality datasets ready to use. If that’s the case, Shaip is your best bet yet. Reach out to us for comprehensive NER datasets to help you develop efficient and advanced ML solutions for your AI models.
[Also Read: What is NLP? How it Works, Benefits, Challenges, Examples
How Does Named-Entity Recognition Work?
Delving into the realm of Named Entity Recognition (NER) unveils a systematic journey comprising several phases:
Tokenization
Initially, the textual data is dissected into smaller units, termed tokens, which can range from words to sentences. For example, the statement “Barack Obama was the president of the USA” is segmented into tokens like “Barack”, “Obama”, “was”, “the”, “president”, “of”, “the”, and “USA”.
Entity Detection
Utilizing a concoction of linguistic guidelines and statistical methodologies, potential named entities are spotlighted. Recognizing patterns like capitalization in names (“Barack Obama”) or distinct formats (like dates) is crucial in this stage.
Entity Classification
Post detection, entities are sorted into predefined categories such as “Person”, “Organization”, or “Location”. Machine learning models, nurtured on labeled datasets, often drive this classification. Here, “Barack Obama” is tagged as a “Person” and “USA” as a “Location”.
Contextual Evaluation
The prowess of NER systems is often amplified by evaluating the surrounding context. For instance, in the phrase “Washington witnessed a historic event”, the context helps discern “Washington” as a location rather than a person’s name.
Post-Evaluation Refinement
Following the initial identification and classification, a post-evaluation refinement may ensue to hone the results. This stage could tackle ambiguities, fuse multi-token entities, or utilize knowledge bases to augment the entity data.
This delineated approach not only demystifies the core of NER but also optimizes the content for search engines, enhancing the visibility of the intricate process that NER embodies.
NER Tools and Libraries Comparison:
Several powerful tools and libraries facilitate NER implementation. Here’s a comparison of some popular options:
| Tool/Library | Description | Strengths | Weaknesses |
|---|---|---|---|
| spaCy | A fast and efficient NLP library in Python. | Excellent performance, easy to use, pre-trained models available. | Limited support for languages other than English. |
| NLTK | A comprehensive NLP library in Python. | Wide range of functionalities, good for educational purposes. | Can be slower than spaCy. |
| Stanford CoreNLP | A Java-based NLP toolkit. | Highly accurate, supports multiple languages. | Requires more computational resources. |
| OpenNLP | A machine learning-based toolkit for NLP. | Supports multiple languages, customizable. | Can be complex to set up. |
Model Training in NER
Model training is at the heart of building effective Named Entity Recognition (NER) systems. This process involves teaching a model to identify and classify named entities—such as people, organizations, and locations—by learning from labeled training data. The success of entity recognition depends heavily on the quality and diversity of this training data, as well as the clarity of predefined categories for each entity type.
During model training, machine learning algorithms analyze textual data annotated with the correct entity labels. Deep learning models, including Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), have become especially popular for NER tasks. These neural networks excel at capturing complex patterns and relationships within text, enabling the NER model to recognize entities with impressive accuracy—even when faced with subtle variations in language.
However, training deep learning models for named entity recognition ner requires large volumes of labeled data, which can be both time-consuming and costly to produce. To address this, techniques like data augmentation and transfer learning are often employed. Data augmentation expands the training dataset by generating new examples from existing data, while transfer learning leverages pre-trained models that have already learned general language patterns, requiring only fine-tuning on domain-specific data.
Ultimately, the effectiveness of a NER model hinges on robust model training, high-quality labeled data, and the careful selection of machine learning or deep learning models suited to the specific entity recognition task.
Model Evaluation in NER
Once a Named Entity Recognition (NER) model has been trained, it’s essential to rigorously evaluate its performance to ensure it accurately identifies and classifies entities in real-world scenarios. Model evaluation in entity recognition typically relies on key metrics such as precision, recall, and F1-score.
- Precision measures how many of the entities identified by the ner model are actually correct, helping to assess the model’s accuracy in predicting named entities.
- Recall evaluates how many of the actual entities present in the text were successfully recognized by the model, indicating its ability to find all relevant entities.
- F1-score provides a balanced measure by combining precision and recall, offering a single metric that reflects both accuracy and completeness.
In addition to these, metrics like overall accuracy and mean average precision can offer further insights into the model’s effectiveness. To ensure the NER system can handle unseen data, it’s important to test the model on a separate validation or test set that was not used during training. Techniques such as cross-validation can also help assess the model’s generalizability across different datasets.
Regular model evaluation not only highlights strengths and weaknesses in entity recognition but also guides further improvements and fine-tuning. By systematically evaluating NER models, organizations can build more reliable and robust systems for extracting entities from diverse text sources.
Best Practices for Effective NER
Achieving high performance in Named Entity Recognition (NER) requires following a set of best practices that address both data quality and model development. Here are some key strategies for effective entity recognition:
- Prioritize High-Quality Training Data: The foundation of any successful NER model is diverse, well-annotated, and representative training data. Labeled data should cover a wide range of entity types and contexts to ensure the model can generalize to new scenarios.
- Thorough Text Preprocessing: Steps like tokenization and part-of-speech tagging help the model better understand the structure of the text, improving its ability to recognize and classify named entities accurately.
- Choose the Right Algorithms: While rule based methods can be effective for simple or highly structured tasks, deep learning models such as RNNs and CNNs often deliver superior results for complex, large-scale NER tasks.
- Leverage Pre-trained Models: Utilizing pre trained models and fine-tuning them on your specific dataset can significantly reduce the need for massive labeled datasets, speeding up development and improving performance.
- Continuous Model Evaluation and Fine-Tuning: Regularly assess your ner model’s performance using robust evaluation metrics, and update it as new data or entity recognition tasks emerge.
- Contextual Awareness: Always consider the context in which entities appear. This helps disambiguate entity names that may have multiple meanings, leading to more accurate entity recognition.
By adhering to these best practices, organizations can build more accurate, adaptable, and efficient NER systems that excel at extracting entities from complex text data.
NER Benefits & Challenges?
Benefits:
- Information Extraction: NER identifies key data, aiding information retrieval.
- Content Organization: It helps categorize content, useful for databases and search engines.
- Enhanced User Experience: NER refines search outcomes and personalizes recommendations.
- Insightful Analysis: It facilitates sentiment analysis and trend detection.
- Automated Workflow: NER promotes automation, saving time and resources.
Limitations / Challenges:
- Ambiguity Resolution: Struggles with distinguishing similar entities like “Amazon” as a river or company.
- Domain-Specific Adaptation: Resource-intensive across diverse domains.
- Language Variations: Effectiveness varies due to slang and regional differences.
- Scarcity of Labeled Data: Needs large labeled datasets for training.
- Handling Unstructured Data: Requires advanced techniques.
- Performance Measurement: Accurate evaluation is complex.
- Real-Time Processing: Balancing speed with accuracy is challenging.
- Context Dependency: Accuracy relies on understanding surrounding text nuances.
- Data Sparsity: Requires substantial labeled datasets, especially for niche areas.
The future of NER
While Named Entity Recognition (NER) is a well-established field, there is still much work to be done. One promising area that we can consider is deep learning techniques including transformers and pre-trained language models, so the performance of NER can be improved further. Advanced models such as biLSTM-CRF and neural networks are now able to understand complex concepts in language, enabling more sophisticated feature extraction for NER tasks. Additionally, few shot learning has the potential to enable NER systems to perform well even with limited labeled data, making it easier to expand NER capabilities to new domains.
Another exciting idea is building custom NER systems for different professions, like doctors or lawyers. As different industries have their own identity types and patterns, creating NER systems in these specific contexts can provide more precise and relevant results, especially when it comes to identifying other entities unique to those domains.
Furthermore, multilingual and cross-lingual NER is also an area of growing faster than ever. With the increasing globalization of business, we need to develop NER systems that can handle diverse linguistic structures and scripts. Future systems will be better at recognizing entities in complex or ambiguous contexts, including nested or domain-specific terminology. Unsupervised learning techniques are also being explored to reduce the reliance on large labeled datasets, further enhancing the adaptability and scalability of NER systems.
Conclusion
Named Entity Recognition (NER) is a powerful NLP technique that identifies and classifies key entities within text, enabling machines to understand and process human language more effectively. From enhancing search engines and chatbots to powering customer support and financial analysis, NER has diverse applications across various industries. While challenges remain in areas like ambiguity resolution and handling unstructured data, ongoing advancements, particularly in deep learning, promise to further refine NER’s capabilities and expand its impact in the future.
Looking to implement NER in your business?
Contact our team for tailored AI Solutions






