Curious how self-driving cars, medical imaging models, LLM copilots or voice assistants get so good? The secret is high-quality, human-validated data annotation.
Analysts now estimate that the combined data collection & labeling market was valued at around USD 3–3.8B in 2023–2024, and is expected to reach roughly USD 17B by 2030 or even USD 29B+ by 2032, implying CAGRs in the high-20% range. Grand View Research Narrower estimates for the data annotation and labeling segment alone put it at about USD 1.6B in 2023, projected to rise to USD 8.5B by 2032 (CAGR ~20.5%). Dataintelo
At the same time, large language models (LLMs), reinforcement learning from human feedback (RLHF), retrieval-augmented generation (RAG) and multimodal AI have changed what “labeled data” means. Instead of just tagging cats in images, teams now curate:
Preference datasets for RLHF
Safety and policy-violation labels
RAG relevance and hallucination evaluations
Long-context reasoning and chain-of-thought supervision
In this environment, data annotation is no longer an afterthought. It’s a core capability that influences:
Model accuracy and reliability
Time-to-market and experimentation speed
Regulatory risk and ethical exposure
Total cost of AI ownership
Why is Data Annotation Critical for AI & ML?
Imagine training a robot to recognize a cat. Without labels, it only sees a noisy grid of pixels. With annotation, those pixels become “cat”, “ears”, “tail”, “background” – structured signals that an AI system can learn from.
Key points:
AI model accuracy: Your model is only as good as the data it’s trained on. High-quality annotation improves pattern recognition, generalization, and robustness.
Diverse applications: Facial recognition, ADAS, sentiment analysis, conversational AI, medical imaging, document understanding, and more all rely on precisely labeled AI training data.
Faster AI development: AI-assisted data labeling tools and human-in-the-loop workflows help you move from concept to production faster by reducing manual effort and incorporating automation where it’s safe to do so.
Stat that still hits in 2026:
According to MIT, up to 80% of data scientists’ time is spent on data preparation and labeling rather than actual modeling—highlighting the central role of annotation in AI.
Data Annotation in 2026: Snapshot for Buyers
Market Size & Growth (What You Need to Know, Not Every Number)
Rather than obsessing over competing forecasts, you need the directional picture:
Data collection & labeling:
~USD 3.0–3.8B in 2023–2024 → ~USD 17–29B by 2030–2032, with CAGRs around 28%.
Data annotation & labeling (services + tools):
~USD 1.6B in 2023 → USD 8.5B by 2032, CAGR ~20.5%.
Put simply: spend on data labeling is among the fastest-growing parts of the AI stack.
Data Annotation Emerging Trends in 2026
2026 Trend / Driver
What It Means
Why It Matters for Buyers
LLMs, RLHF & RAG
Demand for human feedback loops—ranking, rating, correcting LLM outputs; building guardrails, safety labels, and evaluation sets.
Annotation shifts from simple tagging to judgment-based tasks requiring skilled annotators. Essential for LLM quality, safety, and alignment.
Multimodal AI
Models now combine image + video + text + audio + sensor data for richer understanding across industries such as AV, robotics, healthcare, and smart devices.
Buyers need platforms that support multimodal annotation workflows and specialized labeling (LiDAR, video tracking, audio tagging).
Regulated & Safety-Critical AI
Sectors like healthcare, finance, automotive, insurance, and public sector demand strict traceability, privacy, and fairness.
RFPs require security, compliance, data residency, and auditability. Governance becomes a major vendor selection factor.
AI-Assisted Annotation
Foundation models assist annotators by pre-labeling, suggesting corrections, and enabling active learning—achieving major productivity gains.
Provides up to 70% faster labeling and 35–40% lower costs. Enables scalable model-in-the-loop workflows.
Ethics & Workforce Transparency
Growing scrutiny on annotator wages, wellbeing, and mental health, especially for sensitive content.
Ethical sourcing is now mandatory. Vendors must ensure fair pay, safe environments, and responsible content workflows.
What’s Changed Since 2025
Compared with your 2025 guide:
Data annotation is more board-visible. Major AI data providers are reaching multi-billion-dollar valuations and attracting significant funding amid the surge in RLHF and LLM demand.
Vendor risk is in the spotlight. Big tech’s moves away from exclusive dependence on single data labeling providers highlight concerns about data governance, strategic dependence, and security.
Hybrid sourcing is the default. Most enterprises now mix in-house data annotation + outsourcing + crowdsourcing instead of picking one model.
What is Data Annotation?
Data annotation refers to the process of labeling data (text, images, audio, video, or 3D point cloud data) so that machine learning algorithms can process and understand it. For AI systems to work autonomously, they need a wealth of annotated data to learn from.
How It Works in Real-World AI Applications
Self-Driving Cars: Annotated images and LiDAR data help cars detect pedestrians, roadblocks, and other vehicles.
Healthcare AI: Labeled X-rays and CT scans teach models to identify abnormalities.
Voice Assistants: Annotated audio files train speech recognition systems to understand accents, languages, and emotions.
Retail AI: Product and customer sentiment tagging enables personalized recommendations.
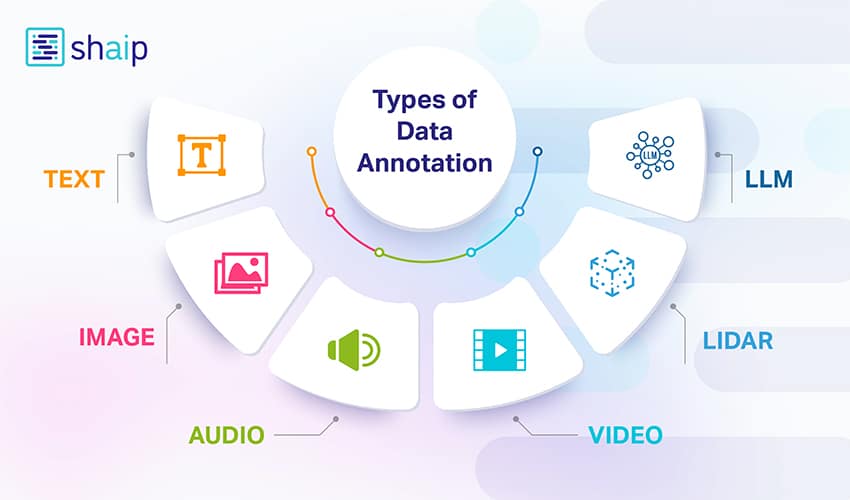
Types of Data Annotation
Data annotation varies depending on the type of data—text, image, audio, video, or 3D spatial data. Each requires a unique annotation method to train machine learning (ML) models accurately. Here’s a breakdown of the most essential types:
Text Annotation
Text annotation is the process of labeling and tagging elements within text so that AI and Natural Language Processing (NLP) models can understand, interpret, and process human language. It involves adding metadata (information about the data) to text, helping models recognize entities, sentiment, intent, relationships, and more.
It’s essential for applications like chatbots, search engines, sentiment analysis, translation, voice assistants, and content moderation.
Type of Text Annotation
Definition
Use Case
Example
Entity Annotation (NER – Named Entity Recognition)
Identifying and labeling key entities (people, places, organizations, dates, etc.) in text.
Used in search engines, chatbots, and information extraction.
In “Apple is opening a new store in Paris,” label "Apple" as Organization and "Paris" as Location.
Part-of-Speech (POS) Tagging
Labeling each word in a sentence with its grammatical role (noun, verb, adjective, etc.).
Improves machine translation, grammar correction, and text-to-speech systems.
In “The cat runs fast,” tag “cat” as Noun, “runs” as Verb, “fast” as Adverb.
Sentiment Annotation
Identifying the emotional tone or opinion expressed in the text.
Used in product reviews, social media monitoring, and brand analysis.
In “The movie was amazing,” tag sentiment as Positive.
Intent Annotation
Labeling the user’s intention in a sentence or query.
Used in virtual assistants and customer support bots.
In “Book me a flight to New York,” tag intent as Travel Booking.
Semantic Annotation
Adding metadata to concepts, linking text to relevant entities or resources.
Used in knowledge graphs, search engine optimization, and semantic search.
Tag “Tesla” with metadata linking it to the concept "Electric Vehicles."
Co-reference Resolution Annotation
Identifying when different words refer to the same entity.
Helps in context understanding for conversational AI and summarization.
In “John said he will come,” tag “he” as referring to “John.”
Linguistic Annotation
Annotating text with phonetics, morphology, syntax, or semantic information.
Used in language learning, speech synthesis, and NLP research.
Adding stress and tone markers to text for speech synthesis.
Toxicity & Content Moderation Annotation
Labeling harmful, offensive, or policy-violating content.
Used in social media moderation and online safety.
Tagging “I hate you” as Offensive content.
Common Tasks:
Chatbot training: Annotate user inputs to help chatbots understand queries and respond accurately.
Document classification: Label documents based on topic or category for easy sorting and automation.
Customer sentiment monitoring: Identify emotional tone in customer feedback (positive, negative, or neutral).
Spam filtering: Tag unwanted or irrelevant messages to train spam detection algorithms.
Entity linking and recognition: Detect and tag names, organizations, or places in text and link them to real-world references.
Image Annotation
Image annotation is the process of labeling or tagging objects, features, or regions within an image so that a computer vision model can recognize and interpret them.
It’s a key step in training AI and machine learning models, especially for applications like autonomous driving, facial recognition, medical imaging, and object detection.
Think of it like teaching a toddler — you point at a picture of a dog and say “dog” until they can recognize dogs on their own. Image annotation does the same for AI.
Type of Image Annotation
Definition
Use Case
Example
Bounding Box Annotation
Drawing a rectangular box around an object to define its position and size.
Object detection in images and videos.
Drawing rectangles around cars in traffic surveillance footage.
Polygon Annotation
Outlining the exact shape of an object with multiple connected points for higher accuracy.
Labeling irregularly shaped objects in satellite or agricultural imagery.
Tracing building boundaries in aerial photographs.
Semantic Segmentation
Labeling every pixel in the image according to its class.
Identifying precise object boundaries in autonomous driving or medical imaging.
Coloring "road" pixels gray, "trees" green, and "cars" blue in a street scene.
Instance Segmentation
Labeling each object instance separately, even if they belong to the same class.
Counting or tracking multiple objects of the same type.
Assigning Person 1, Person 2, Person 3 in a crowd image.
Keypoint & Landmark Annotation
Marking specific points of interest on an object (e.g., facial features, body joints).
Connecting head, shoulders, elbows, and knees to track a runner’s motion.
Common Tasks:
Object detection: Identify and locate objects in an image using bounding boxes.
Scene understanding: Label various components of a scene for contextual image interpretation.
Face detection and recognition: Detect human faces and recognize individuals based on facial features.
Image classification: Categorize entire images based on visual content.
Medical image diagnosis: Label anomalies in scans like X-rays or MRIs to assist in clinical diagnosis.
Image Captioning: The process of analyzing an image and generating a descriptive sentence about its content. This involves both object detection and contextual understanding.
Optical Character Recognition (OCR): Extracting printed or handwritten text from scanned images, photos, or documents and converting it into machine-readable text.
Video Annotation
Video annotation is the process of labeling and tagging objects, events, or actions across frames in a video so that AI and computer vision models can detect, track, and understand them over time.
Unlike image annotation (which deals with static images), video annotation considers motion, sequence, and temporal changes — helping AI models analyze moving objects and activities.
It’s used in autonomous vehicles, surveillance, sports analytics, retail, robotics, and medical imaging.
Type of Video Annotation
Definition
Use Case
Example
Frame-by-Frame Annotation
Manually labeling each frame in a video to track objects.
Used when high precision is required for moving objects.
In a wildlife documentary, labeling each frame to track a tiger’s movement.
Bounding Box Tracking
Drawing rectangular boxes around moving objects and tracking them across frames.
Used in traffic monitoring, retail analytics, and security.
Tracking cars in CCTV footage at an intersection.
Polygon Tracking
Using polygons to outline moving objects for higher accuracy than bounding boxes.
Used in sports analytics, drone footage, and object detection with irregular shapes.
Tracking a football in a game using a polygon shape.
3D Cuboid Tracking
Drawing cube-like boxes to capture the object’s position, orientation, and dimensions in 3D space over time.
Used in autonomous driving and robotics.
Tracking a moving truck’s position and size in dashcam footage.
Keypoint & Skeletal Tracking
Labeling and connecting specific points (joints, landmarks) to track body movement.
Used in human pose estimation, sports performance analysis, and healthcare.
Tracking a sprinter’s arm and leg movement during a race.
Semantic Segmentation in Video
Labeling every pixel in each frame to classify objects and their boundaries.
Used in autonomous vehicles, AR/VR, and medical imaging.
Labeling road, pedestrians, and vehicles in every video frame.
Instance Segmentation in Video
Similar to semantic segmentation but also separates each object instance.
Used for crowd monitoring, behavior tracking, and object counting.
Labeling each person individually in a crowded train station.
Event or Action Annotation
Tagging specific activities or events in a video.
Used in sports highlights, surveillance, and retail behavior analysis.
Labeling "goal scored" moments in a soccer match.
Common Tasks:
Activity detection: Identify and tag human or object actions within a video.
Object tracking over time: Follow and label objects frame by frame as they move through video footage.
Behavior analysis: Analyze patterns and behaviors of subjects in video feeds.
Safety surveillance: Monitor video footage to detect security breaches or unsafe conditions.
Event detection in sports/public spaces: Flag specific actions or events like goals, fouls, or crowd movements.
Video Classification (Tagging): Video classification involves sorting video content into specific categories, which is crucial for moderating online content and ensuring a safe experience for users.
Video Captioning: Similar to how we caption images, video captioning involves turning video content into descriptive text.
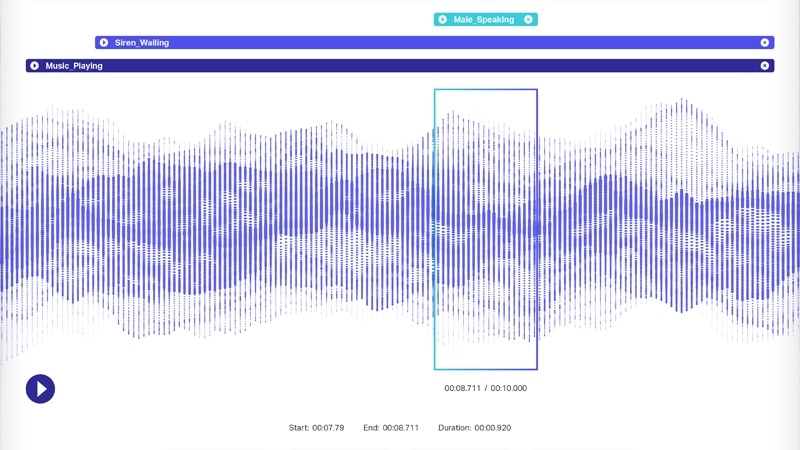
Audio Annotation
Audio annotation is the process of labeling and tagging sound recordings so that AI and speech recognition models can interpret spoken language, environmental sounds, emotions, or events.
It can involve marking speech segments, identifying speakers, transcribing text, tagging emotions, or detecting background noises.
Audio annotation is widely used in virtual assistants, transcription services, call center analytics, language learning, and sound recognition systems.
Type of Audio Annotation
Definition
Use Case
Example
Speech-to-Text Transcription
Converting spoken words in an audio file into written text.
Used in subtitles, transcription services, and voice assistants.
Transcribing a podcast episode into text format.
Speaker Diarization
Identifying and labeling different speakers in an audio file.
Used in call centers, interviews, and meeting transcription.
Tagging “Speaker 1” and “Speaker 2” in a customer support call.
Phonetic Annotation
Labeling phonemes (smallest units of sound) in speech.
Used in language learning apps and speech synthesis.
Marking the /th/ sound in the word “think.”
Emotion Annotation
Tagging emotions expressed in speech (happy, sad, angry, neutral, etc.).
Used in sentiment analysis, call quality monitoring, and mental health AI tools.
Labeling a customer’s tone as “frustrated” in a support call.
Intent Annotation (Audio)
Identifying the purpose of a spoken request or command.
Used in virtual assistants, chatbots, and voice search.
In “Play jazz music,” tagging the intent as “Play Music.”
Environmental Sound Annotation
Labeling background or non-speech sounds in an audio recording.
Used in sound classification systems, smart cities, and security.
Tagging “dog barking” or “car horn” in street recordings.
Timestamp Annotation
Adding time markers to specific words, phrases, or events in audio.
Used in video editing, transcription alignment, and training data for ASR models.
Marking the time “00:02:15” when a specific word is spoken in a speech.
Language & Dialect Annotation
Tagging the language, dialect, or accent of the audio.
Used in multilingual speech recognition and translation.
Labeling a recording as “Spanish – Mexican Accent.”
Common Tasks:
Voice recognition: Identify individual speakers and match them to known voices.
Emotion detection: Analyze tone and pitch to detect speaker emotions like anger or joy.
Audio classification: Categorize non-speech sounds such as claps, alarms, or engine noises.
Language identification: Recognize which language is being spoken in an audio clip.
Multilingual audio transcription: Convert speech from multiple languages into written text.
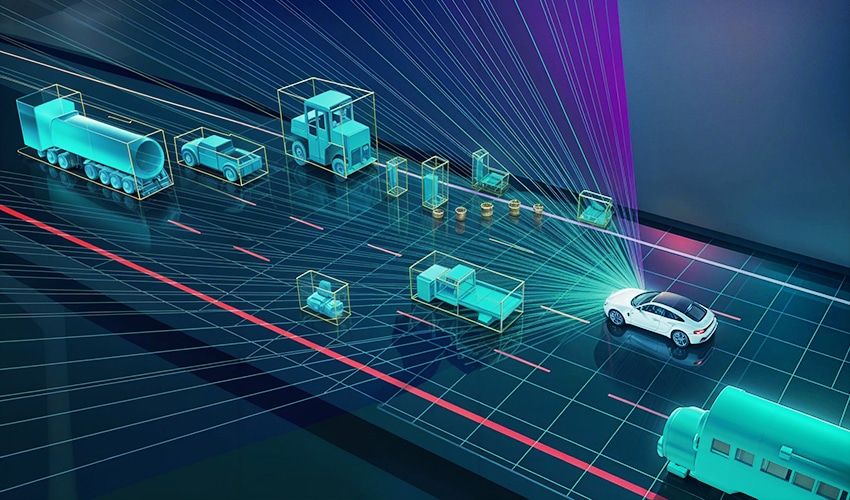
Lidar Annotation
LiDAR (Light Detection and Ranging) annotation is the process of labeling 3D point cloud data collected by LiDAR sensors so AI models can detect, classify, and track objects in a three-dimensional environment.
LiDAR sensors emit laser pulses that bounce off surrounding objects, capturing distance, shape, and spatial positioning to create a 3D representation of the environment (point cloud).
Annotation helps train AI for autonomous driving, robotics, drone navigation, mapping, and industrial automation.
3D Point Cloud Labeling
Definition: Labeling clusters of spatial points in a 3D environment. Example: Identifying a cyclist in LiDAR data from a self-driving car.
Cuboids
Definition: Placing 3D boxes around objects in a point cloud to estimate dimensions and orientation. Example: Creating a 3D box around a pedestrian crossing the street.
Semantic & Instance Segmentation
Definition:\n- Semantic: Assigns class to each point (e.g., road, tree).\n- Instance: Differentiates between objects of the same class (e.g., Car 1 vs. Car 2). Example: Separating individual vehicles in a crowded parking lot.
Common Tasks:
3D object detection: Identify and locate objects in 3D space using point cloud data.
Obstacle classification: Tag different types of obstacles like pedestrians, vehicles, or barriers.
Path planning for robots: Annotate safe and optimal paths for autonomous robots to follow.
Environmental mapping: Create annotated 3D maps of surroundings for navigation and analysis.
Motion prediction: Use labeled movement data to anticipate object or human trajectories.
LLM (Large Language Model) Annotation
LLM (Large Language Model) annotation is the process of labeling, curating, and structuring text data so that large-scale AI language models (like GPT, Claude, or Gemini) can be trained, fine-tuned, and evaluated effectively.
It goes beyond basic text annotation by focusing on complex instructions, context understanding, multi-turn dialogue structures, and reasoning patterns that help LLMs perform tasks such as answering questions, summarizing content, generating code, or following human instructions.
LLM annotation often involves human-in-the-loop workflows to ensure high accuracy and relevance, especially for tasks involving nuanced judgment.
Type of Annotation
Definition
Use Case
Example
Instruction Annotation
Crafting and labeling prompts with corresponding ideal responses to teach the model how to follow instructions.
Used in training LLMs for chatbot tasks, customer support, and Q&A systems.
Prompt: “Summarize this article in 50 words.” → Annotated Response: Concise summary matching guidelines.
Classification Annotation
Assigning categories or labels to text based on its meaning, tone, or topic.
Used in content moderation, sentiment analysis, and topic categorization.
Labeling a tweet as “Positive” sentiment and “Sports” topic.
Entity & Metadata Annotation
Tagging named entities, concepts, or metadata within training data.
Used for knowledge retrieval, fact extraction, and semantic search.
In “Tesla launched a new model in 2024,” label “Tesla” as Organization and “2024” as Date.
Reasoning Chain Annotation
Creating step-by-step explanations for how to reach an answer.
Used in training LLMs for logical reasoning, problem solving, and math tasks.
Structuring multi-turn conversations with context retention, intent recognition, and correct responses.
Used in conversational AI, virtual assistants, and interactive bots.
A customer asks about shipping → AI provides relevant follow-up questions and answers.
Error Annotation
Identifying mistakes in LLM outputs and labeling them for retraining.
Used for improving model accuracy and reducing hallucinations.
Marking “Paris is the capital of Italy” as a factual error.
Safety & Bias Annotation
Tagging harmful, biased, or policy-violating content for filtering and alignment.
Used to make LLMs safer and more ethical.
Labeling “offensive joke” content as unsafe.
Common Tasks:
Instruction-following evaluation: Check how well the LLM executes or follows a user prompt.
Hallucination detection: Identify when an LLM generates inaccurate or made-up information.
Prompt quality rating: Evaluate the clarity and effectiveness of user prompts.
Factual correctness validation: Ensure AI responses are factually accurate and verifiable.
Toxicity flagging: Detect and label harmful, offensive, or biased AI-generated content.
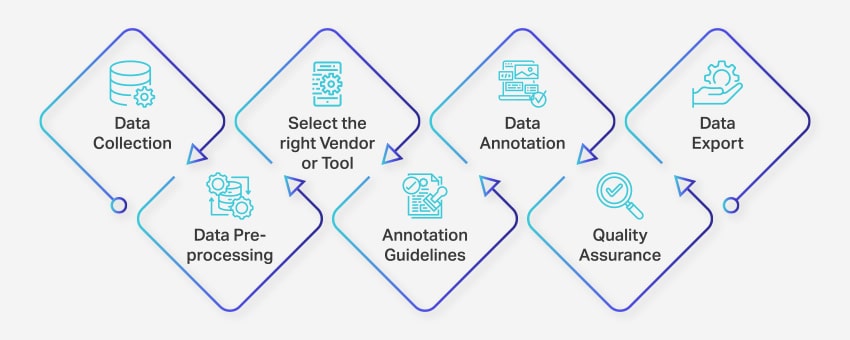
Step-by-Step Data Labeling / Data Annotation Process for Machine Learning Success
The data annotation process involves a series of well-defined steps to ensure high-quality and accurate data labeling process for machine learning applications. These steps cover every aspect of the process, from unstructured data collection to exporting the annotated data for further use. Effective MLOps practices can streamline this process and improve overall efficiency.
Here’s how data annotation team works:
Data Collection: The first step in the data annotation process is to gather all the relevant data, such as images, videos, audio recordings, or text data, in a centralized location.
Data Preprocessing: Standardize and enhance the collected data by deskewing images, formatting text, or transcribing video content. Preprocessing ensures the data is ready for annotation task.
Select the Right Vendor or Tool: Choose an appropriate data annotation tool or vendor based on your project’s requirements.
Annotation Guidelines: Establish clear guidelines for annotators or annotation tools to ensure consistency and accuracy throughout the process.
Annotation: Label and tag the data using human annotators or data annotation platform, following the established guidelines.
Quality Assurance (QA): Review the annotated data to ensure accuracy and consistency. Employ multiple blind annotations, if necessary, to verify the quality of the results.
Data Export: After completing the data annotation, export the data in the required format. Platforms like Nanonets enable seamless data export to various business software applications.
The entire data annotation process can range from a few days to several weeks, depending on the project’s size, complexity, and available resources.
Advanced Features to Look for in Enterprise Data Annotation Platforms / Data Labeling Tools
Choosing the right data annotation tool can make or break your AI project. It’s not just the quality of your dataset—your data labeling platform directly impacts accuracy, speed, cost, and scalability. Here’s a simplified list of the core features every modern enterprise should look for.
Dataset Management
A good platform should make it easy to import, organize, version, and export large datasets.
Look for:
Bulk upload support (images, video, audio, text, 3D)
Sorting, filtering, merging, and dataset cloning
Strong data versioning to track changes over time
Export to standard ML formats (JSON, COCO, YOLO, CSV, etc.)
Multiple Annotation Techniques
Your tool should support all major data types—computer vision, NLP, audio, video, and 3D.
Support for LLM/RLHF tasks (ranking, scoring, safety labeling)
AI-assisted labeling is now standard—auto-annotation to speed up work and reduce manual effort.
Built-In Quality Control
Great platforms include QA features to keep labels consistent and accurate.
Key capabilities:
Reviewer workflows (annotator → reviewer → QA)
Label consensus & conflict resolution
Commenting, feedback threads, and change history
Ability to revert to earlier dataset versions
Security & Compliance
Annotation often involves sensitive data, so security must be airtight.
Look for:
Role-based access control (RBAC)
SSO, audit logs, and secure data storage
Prevention of unauthorized downloads
Compliance with HIPAA, GDPR, SOC 2, or your industry standards
Support for private cloud or on-premise deployment
Workforce & Project Management
A modern tool should help manage your annotation team and workflow.
Essential features:
Task assignment & queue management
Progress tracking and productivity metrics
Collaboration features for distributed teams
Simple, intuitive UI with a low learning curve
What are the Benefits of Data Annotation?
Data annotation is crucial to optimizing machine learning systems and delivering improved user experiences. Here are some key benefits of data annotation:
Improved Training Efficiency: Data labeling helps machine learning models be better trained, enhancing overall efficiency and producing more accurate outcomes.
Increased Precision: Accurately annotated data ensures that algorithms can adapt and learn effectively, resulting in higher levels of precision in future tasks.
Reduced Human Intervention: Advanced data annotation tools significantly decrease the need for manual intervention, streamlining processes and reducing associated costs.
Thus, data annotation contributes to more efficient and precise machine learning systems while minimizing the costs and manual effort traditionally required to train AI models.
Quality Control in Data Annotation
Shaip ensures top-notch quality through multiple stages of quality control to ensure quality in data annotation projects.
Initial Training: Annotators are thoroughly trained on project-specific guidelines.
Ongoing Monitoring: Regular quality checks during the annotation process.
Final Review: Comprehensive reviews by senior annotators and automated tools to ensure accuracy and consistency.
Moreover AI can also identify inconsistencies in human annotations and flag them for review, ensuring higher overall data quality. (e.g., AI can detect discrepancies in how different annotators label the same object in an image). So with human and AI the quality of annotation can be improved significantly while reducing the overall time taken to complete the projects.
Overcoming Common Data Annotation Challenges
Data annotation plays a critical role in the development and accuracy of AI and machine learning models. However, the process comes with its own set of challenges:
Cost of annotating data: Data annotation can be performed manually or automatically. Manual annotation requires significant effort, time, and resources, which can lead to increased costs. Maintaining the quality of the data throughout the process also contributes to these expenses.
Accuracy of annotation: Human errors during the annotation process can result in poor data quality, directly affecting the performance and predictions of AI/ML models. A study by Gartner highlights that poor data quality costs companies up to 15% of their revenue.
Scalability: As the volume of data increases, the annotation process can become more complex and time-consuming with larger datasets, especially when working with multimodal data.. Scaling data annotation while maintaining quality and efficiency is challenging for many organizations.
Data privacy and security: Annotating sensitive data, such as personal information, medical records, or financial data, raises concerns about privacy and security. Ensuring that the annotation process complies with relevant data protection regulations and ethical guidelines is crucial to avoiding legal and reputational risks.
Managing diverse data types: Handling various data types like text, images, audio, and video can be challenging, especially when they require different annotation techniques and expertise. Coordinating and managing the annotation process across these data types can be complex and resource-intensive.
Organizations can understand and address these challenges to overcome the obstacles associated with data annotation and improve the efficiency and effectiveness of their AI and machine learning projects.
Data Annotation In-House vs. Outsourcing
When it comes to executing data annotation at scale, organizations must choose between building in-house annotation teams or outsourcing to external vendors. Each approach has distinct pros and cons based on cost, quality control, scalability, and domain expertise.
In-House Data Annotation
✅ Pros
Tighter Quality Control: Direct supervision ensures higher accuracy and consistent output.
Domain Expertise Alignment: Internal annotators can be trained specifically for industry or project context (e.g., medical imaging or legal texts).
Data Confidentiality: Greater control over sensitive or regulated data (e.g., HIPAA, GDPR).
Custom Workflows: Fully adaptable processes and tools aligned with internal development pipelines.
❌ Cons
Higher Operational Costs: Recruitment, training, salaries, infrastructure, and management.
Limited Scalability: Harder to ramp up for sudden large-volume projects.
Longer Setup Time: Takes months to build and train a competent in-house team.
🛠️ Best For:
High-stakes AI models (e.g., medical diagnostics, autonomous driving)
Projects with continuous and consistent annotation needs
Organizations with strict data governance policies
Outsourced Data Annotation
✅ Pros
Cost-Effective: Benefit from economies of scale, especially for large datasets.
Faster Turnaround: Pre-trained workforce with domain experience enables quicker delivery.
Scalability: Easily ramp up teams for high-volume or multi-language projects.
Access to Global Talent: Leverage annotators with multilingual or specialized skills (e.g., African dialects, regional accents, rare languages).
❌ Cons
Data Security Risks: Depends on the vendor’s privacy and security protocols.
Communication Gaps: Time zone or cultural differences can affect feedback loops.
Less Control: Reduced ability to enforce internal quality benchmarks unless robust SLAs and QA systems are in place.
🛠️ Best For:
One-off or short-term labeling projects
Projects with limited internal resources
Companies seeking rapid, global workforce expansion
In-House vs. Outsourced Data Annotation
Factor
In-House
Outsourcing
Setup Time
High (requires hiring, training, and infrastructure setup)
Low (vendors have ready-to-go teams)
Cost
High (fixed salaries, benefits, software/tools)
Lower (variable, project-based pricing)
Scalability
Limited by internal team capacity
Highly scalable on demand
Data Control
Maximum (local data handling and storage)
Depends on vendor policies and infrastructure
Compliance & Security
Easier to ensure direct compliance with HIPAA, GDPR, SOC 2, etc.
Must verify vendor’s compliance certifications and data handling processes
Domain Knowledge
High (can train staff for niche, industry-specific requirements)
Varies — depends on vendor specialization in your domain
Quality Assurance
Direct, real-time oversight
Requires robust QA processes, Service Level Agreements (SLAs), and audits
Management Effort
High (HR, process design, workflow monitoring)
Low (vendor manages workforce, tools, and workflows)
Technology & Tools
Limited by internal budget and expertise
Often includes access to advanced AI-assisted labeling tools
Talent Availability
Limited to local hiring pool
Access to global talent and multilingual annotators
Time Zone Coverage
Typically limited to office hours
24/7 coverage possible with global vendor teams
Turnaround Time
Slower ramp-up due to hiring/training
Faster project kickoff and delivery due to existing team setup
Ideal For
Long-term, sensitive, complex projects with strict data control
Short-term, multilingual, high-volume, or rapid scaling projects
Hybrid Approach: Best of Both Worlds?
Many successful AI teams today adopt a hybrid approach:
Keep core team in-house for high-quality control and edge-case decisions.
Outsource bulk tasks (e.g., object bounding or sentiment labeling) to trusted vendors for speed and scale.
How to Choose the Right Data Annotation Tool
Selecting the ideal data annotation tool is a critical decision that can make or break your AI project’s success. With a rapidly expanding market and increasingly sophisticated requirements, here’s a practical, up-to-date guide to help you navigate your options and find the best fit for your needs.
A data annotation/labeling tool is a cloud-based or on-premise platform used to annotate high-quality training data for machine learning models. While many rely on external vendors for complex tasks, some use custom-built or open-source tools. These tools handle specific data types like images, videos, text, or audio, offering features like bounding boxes and polygons for efficient labeling.
1. Define Your Use Case and Data Types
Start by clearly outlining your project’s requirements:
What types of data will you be annotating—text, images, video, audio, or a combination?
Does your use case demand specialized annotation techniques, such as semantic segmentation for images, sentiment analysis for text, or transcription for audio?
Choose a tool that not only supports your current data types but is also flexible enough to accommodate future needs as your projects evolve.
2. Evaluate Annotation Capabilities and Techniques
Look for platforms that offer a comprehensive suite of annotation methods relevant to your tasks:
For computer vision: bounding boxes, polygons, semantic segmentation, cuboids, and keypoint annotation.
For NLP: entity recognition, sentiment tagging, part-of-speech tagging, and coreference resolution.
For audio: transcription, speaker diarization, and event tagging.
Advanced tools now often include AI-assisted or automated labeling features, which can speed up annotation and improve consistency.
3. Assess Scalability and Automation
Your tool should be able to handle increasing data volumes as your project grows:
Does the platform offer automated or semi-automated annotation to boost speed and reduce manual effort?
Can it manage enterprise-scale datasets without performance bottlenecks?
Are there built-in workflow automation and task assignment features to streamline large team collaborations?
4. Prioritize Data Quality Control
High-quality annotations are essential for robust AI models:
Seek tools with embedded quality control modules, such as real-time review, consensus workflows, and audit trails.
Look for features that support error tracking, remove duplicate, version control, and easy feedback integration.
Ensure the platform allows you to set and monitor quality standards from the outset, minimizing error margins and bias.
5. Consider Data Security and Compliance
With growing concerns about privacy and data protection, security is non-negotiable:
The tool should offer robust data access controls, encryption, and compliance with industry standards (like GDPR or HIPAA).
Evaluate where and how your data is stored-cloud, local, or hybrid options-and whether the tool supports secure sharing and collaboration.
6. Decide on Workforce Management
Determine who will annotate your data:
Does the tool support both in-house and outsourced annotation teams?
Are there features for task assignment, progress tracking, and collaboration?
Consider the training resources and support provided for onboarding new annotators.
7. Choose the Right Partner, Not Just a Vendor
The relationship with your tool provider matters:
Look for partners who offer proactive support, flexibility, and a willingness to adapt as your needs change.
Assess their experience with similar projects, responsiveness to feedback, and commitment to confidentiality and compliance.
Key Takeaway
The best data annotation tool for your project is one that aligns with your specific data types, scales with your growth, guarantees data quality and security, and integrates seamlessly into your workflow. By focusing on these core factors-and choosing a platform that evolves with the latest AI trends-you’ll set your AI initiatives up for long-term success.
Industry-Specific Data Annotation Use Cases
Data annotation is not one-size-fits-all — each industry has unique datasets, goals, and annotation requirements. Below are key industry-specific use cases with real-world relevance and practical impact.
Healthcare
Use Case: Annotating medical imagery and patient records
Description:
Annotate X-rays, CT scans, MRIs, and pathology slides for training diagnostic AI models.
Label entities in Electronic Health Records (EHRs), like symptoms, drug names, and dosages using Named Entity Recognition (NER).
Transcribe and classify clinical conversations for speech-based medical assistants.
Impact: Improves early diagnosis, accelerates treatment planning, and reduces human error in radiology and documentation.
Automotive & Transportation
Use Case: Powering ADAS and autonomous vehicle systems
Description:
Use LiDAR point cloud labeling to detect 3D objects like pedestrians, road signs, and vehicles.
Annotate video feeds for object tracking, lane detection, and driving behavior analysis.
Train models for driver monitoring systems (DMS) via face and eye movement recognition.
Impact: Enables safer autonomous driving systems, improves road navigation, and reduces collisions through precise annotations.
Retail & E-commerce
Use Case: Enhancing customer experience and personalization
Description:
Use text annotation on user reviews for sentiment analysis to fine-tune recommendation engines.
Annotate product images for catalog classification, visual search, and inventory tagging.
Track in-store footfall or customer behavior using video annotation in smart retail setups.
Annotate genomic data or biological text for named entities like genes, proteins, and compounds.
Label clinical trial documents to extract patient insights and trial outcomes.
Process and classify chemical diagrams or lab experiment notes using OCR and image annotation.
Impact: Accelerates biomedical research, supports clinical data mining, and reduces manual effort in R&D.
Contact Centers & Customer Support
Use Case: Improving automation and customer insights
Description:
Transcribe and annotate customer support calls for emotion detection, intent classification, and training chatbots.
Tag common complaint categories to prioritize issue resolution.
Annotate live chats to train conversational AI and auto-response systems.
Impact: Increases support efficiency, reduces resolution times, and enables 24/7 customer assistance with AI.
What are the best practices for data annotation?
To ensure the success of your AI and machine learning projects, it’s essential to follow best practices for data annotation. These practices can help enhance the accuracy and consistency of your annotated data:
Choose the appropriate data structure: Create data labels that are specific enough to be useful but general enough to capture all possible variations in data sets.
Provide clear instructions: Develop detailed, easy-to-understand data annotation guidelines and best practices to ensure data consistency and accuracy across different annotators.
Optimize the annotation workload: Since annotation can be costly, consider more affordable alternatives, such as working with data collection services that offer pre-labeled datasets.
Collect more data when necessary: To prevent the quality of machine learning models from suffering, collaborate with data collection companies to gather more data if required.
Outsource or crowdsource: When data annotation requirements become too large and time-consuming for internal resources, consider outsourcing or crowdsourcing.
Combine human and machine efforts: Use a human-in-the-loop approach with data annotation software to help human annotators focus on the most challenging cases and increase the diversity of the training data set.
Prioritize quality: Regularly test your data annotations for quality assurance purposes. Encourage multiple annotators to review each other’s work for accuracy and consistency in labeling datasets.
Ensure compliance: When annotating sensitive data sets, such as images containing people or health records, consider privacy and ethical issues carefully. Non-compliance with local rules can damage your company’s reputation.
Adhering to these data annotation best practices can help you guarantee that your data sets are accurately labeled, accessible to data scientists, and ready to fuel your data-driven projects.
Real-World Case Studies: Shaip’s Impact in Data Annotation
Clinical Data Annotation
Use Case: Automating Prior Authorization for Healthcare Providers
Project Scope: Annotation of 6,000 medical records
Duration: 6 months
Annotation Focus:
Structured extraction and labeling of CPT codes, diagnoses, and InterQual criteria from unstructured clinical text
Identification of medically necessary procedures within patient records
Entity tagging and classification in medical documents (e.g., symptoms, procedures, medications)
Process:
Used clinical annotation tools with HIPAA-compliant access
Employed certified medical annotators (nurses, clinical coders)
Double-pass QA with annotation reviews every 2 weeks
Annotation guidelines aligned with InterQual® and CPT standards
Outcome:
Delivered >98% annotation accuracy
Reduced processing delays in prior authorizations
Enabled effective training of AI models for document classification and triage
LiDAR Annotation for Autonomous Vehicles
Use Case: 3D Object Recognition in Urban Driving Conditions
Project Scope: Annotated 15,000 LiDAR frames (combined with multi-view camera inputs)
Duration: 4 months
Annotation Focus:
3D point cloud labeling using cuboids for cars, pedestrians, cyclists, traffic signals, road signs
Instance segmentation of complex objects in multi-class environments
Multi-frame object ID consistency (for tracking across sequences)
Annotated occlusions, depth, and overlapping objects
Process:
Used proprietary LiDAR annotation tools
Team of 50 trained annotators + 10 QA specialists
Annotation assisted by AI models for initial bounding/cuboid suggestions
Manual correction and precision tagging ensured edge-level detail
Outcome:
Achieved 99.7% annotation accuracy
Delivered >450,000 labeled objects
Enabled robust perception model development with reduced training cycles
Content Moderation Annotation
Use Case: Training Multilingual AI Models to Detect Toxic Content
Project Scope: 30,000+ text and voice-based content samples in multiple languages
Annotation Focus:
Classification of content into categories like toxic, hate speech, profanity, sexually explicit, and safe
Entity-level tagging for context-aware classification
Sentiment and intent labeling on user-generated content
Language tagging and translation verification
Process:
Multilingual annotators trained in cultural/contextual nuances
Tiered review system with escalation for ambiguous cases
Used internal annotation platform with real-time QA checks
Outcome:
Built high-quality ground truth datasets for content filtering
Ensured cultural sensitivity and labeling consistency across locales
Supported scalable moderation systems for diverse geographies
Expert Insights on Data Annotation
What Industry Leaders Say About Building Accurate, Scalable, and Ethical AI Through Annotation
In healthcare AI, the margin for error is almost zero. For annotation to be effective, it’s critical to use medically trained annotators, follow clinical coding standards like ICD-10 or SNOMED, and ensure PHI is de-identified. High-quality annotation is not just about labeling—it’s about patient safety, regulatory compliance, and enabling real clinical insights.
To ensure consistency in data labeling and reduce bias, we implement strict guidelines, conduct regular reviews, and re train annotators. We also anonymize datasets, limit annotator hours to prevent fatigue, and provide mental health support to our team.
Comprehensive training on unconscious biases, ensuring diverse annotator teams, and regular audits are key strategies in maintaining high quality data labeling. This approach helped us achieve more balanced sentiment analysis in our customer feedback models.
Poor data labeling leads to biased AI models and flawed outcomes. To counter this, we assemble diverse annotator groups and provide clear guidelines to reduce bias. Using multiple annotators per data item helps average out individual biases, and iterative improvements further reduce bias, helping mitigate the risks of poor data labeling.
Data annotation is the process of labeling data to train machine learning models effectively
High-quality data annotation directly impacts AI model accuracy and performance
The global data annotation market is projected to reach $3.4 billion by 2028, growing at 38.5% CAGR
Choosing the right annotation tools and techniques can reduce project costs by up to 40%
Implementation of AI-assisted annotation can improve efficiency by 60-70% for most projects
We honestly believe this guide was resourceful to you and that you have most of your questions answered. However, if you’re still not convinced about a reliable vendor, look no further.
We, at Shaip, are a premier data annotation company. We have experts in the field who understand data and its allied concerns like no other. We could be your ideal partners as we bring to table competencies like commitment, confidentiality, flexibility and ownership to each project or collaboration.
So, regardless of the type of data you intend to get accurate annotations for, you could find that veteran team in us to meet your demands and goals. Get your AI models optimized for learning with us.
Transform Your AI Projects with Expert Data Annotation Services
Ready to elevate your machine learning and AI initiatives with high-quality annotated data? Shaip offers end-to-end data annotation solutions tailored to your specific industry and use case.
Why Partner with Shaip for Your Data Annotation Needs:
Domain Expertise: Specialized annotators with industry-specific knowledge
Scalable Workflows: Handle projects of any size with consistent quality
Customized Solutions: Tailored annotation processes for your unique needs
Security & Compliance: HIPAA, GDPR, and ISO 27001 compliant processes
Flexible Engagement: Scale up or down based on project requirements
Let’s Talk
Frequently Asked Questions (FAQ)
1. What is data annotation or Data labeling?
Data Annotation or Data Labeling is the process that makes data with specific objects recognizable by machines so as to predict the outcome. Tagging, transcribing or processing objects within textual, image, scans, etc. enable algorithms to interpret the labeled data and get trained to solve real business cases on its own without human intervention.
2. What is annotated data?
In machine learning (both supervised or unsupervised), labeled or annotated data is tagging, transcribing or processing the features you want your machine learning models to understand and recognize so as to solve real world challenges.
3. Who is a Data Annotator?
A data annotator is a person who works tirelessly to enrich the data so as to make it recognizable by machines. It may involve one or all of the following steps (subject to the use case in hand and the requirement): Data Cleaning, Data Transcribing, Data Labeling or Data Annotation, QA etc.
4. Why is data annotation important for AI and ML?
AI models require labeled data to recognize patterns and perform tasks like classification, detection, or prediction. Data annotation ensures that models are trained on high-quality, structured data, leading to better accuracy, performance, and reliability.
5. How do I ensure the quality of annotated data?
Provide clear annotation guidelines to your team or vendor.
Use quality assurance (QA) processes, such as blind reviews or consensus models.
Leverage AI tools to flag inconsistencies and errors.
Perform regular audits and sampling to ensure data accuracy.
6. What is the difference between manual and automated annotation?
Manual Annotation: Done by human annotators, ensuring high accuracy but requiring significant time and cost.
Automated Annotation: Uses AI models for labeling, offering speed and scalability. However, it may require human review for complex tasks.
A semi-automatic approach (human-in-the-loop) combines both methods for efficiency and precision.
7. What are pre-labeled datasets, and should I use them?
Pre-labeled datasets are ready-made datasets with annotations, often available for common use cases. They can save time and effort but may need customization to fit specific project requirements.
8. How does data annotation differ for supervised, unsupervised, and semi-supervised learning?
In supervised learning, labeled data is crucial for training models. Unsupervised learning typically does not require annotation, while semi-supervised learning uses a mix of labeled and unlabeled data.
9. How is generative AI impacting data annotation?
Generative AI is increasingly used to pre-label data, while human experts refine and validate annotations, making the process faster and more cost-efficient.
10. What ethical and privacy concerns should be considered?
Annotating sensitive data requires strict compliance with privacy regulations, robust data security, and measures to minimize bias in labeled datasets.
11. How should I budget for data annotation?
Budget depends on how much data you need labeled, the complexity of the task, the type of data (text, image, video), and whether you use in-house or outsourced teams. Using AI tools can reduce costs. Expect prices to vary widely based on these factors.
12. What hidden costs should I watch out for?
Costs can include data security, fixing annotation errors, training annotators, and managing large projects.
13. How much annotated data do I need?
It depends on your project’s goals and model complexity. Start with a small labeled set, train your model, then add more data as needed to improve accuracy. More complex tasks usually need more data.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Cookie Preferences
Manage your cookie preferences below:
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Geolocation Config
This cookie is used to store the consent settings based on the visitor's location.
180 days
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
180 days
Google Tag Manager simplifies the management of marketing tags on your website without code changes.
Name
Description
Duration
TRINITY_USER_ID
-
TRINITY_USER_DATA
-
td
Registers statistical data on users' behaviour on the website. Used for internal analytics by the website operator.
session
cookiePreferences
Registers cookie preferences of a user
2 years
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
Google Ads is an online advertising platform that enables businesses to create targeted ads displayed on Google search results and partner sites.
Targeting cookie. Used to create a user profile and display relevant and personalised Google Ads to the user.
2 years
FPGCLAW
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 Days
FPGCLGB
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 Days
_gac_gb_
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 Days
_gcl_gb
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 Days
_gcl_gs
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 Days
_gcl_aw
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 Days
Conversion
Google uses cookies for advertising, including serving and rendering ads, personalizing ads (depending on your ad settings at g.co/adsettings), limiting the number of times an ad is shown to a user, muting ads you have chosen to stop seeing, and measuring the effectiveness of ads.
90 days
__Secure-3PSID
Targeting cookie. Used to profile the interests of website visitors and display relevant and personalised Google ads.
2 years
__Secure-1PSID
Targeting cookie. Used to create a user profile and display relevant and personalised Google Ads to the user.
2 years
__Secure-1PSIDTS
Targeting cookie. Used to create a user profile and display relevant and personalised Google Ads to the user.
2 years
__Secure-3PSIDTS
Targeting cookie. Used to create a user profile and display relevant and personalised Google Ads to the user.
2 years
__Secure-3PSIDCC
Targeting cookie. Used to create a user profile and display relevant and personalised Google Ads to the user.
2 years
ADS_VISITOR_ID
Cookie required to use the options and on-site web services
2 months
AEC
AEC cookies ensure that requests within a browsing session are made by the user, and not by other sites. These cookies prevent malicious sites from acting on behalf of a user without that user's knowledge.
6 months
__Secure-3PAPISID
Profiles the interests of website visitors to serve relevant and personalised ads through retargeting.
2 years
__Secure-1PSIDCC
Targeting cookie. Used to create a user profile and display relevant and personalised Google Ads to the user.