
What is Text Annotation in Machine Learning?
Text annotation in machine learning refers to adding metadata or labels to raw textual data to create structured datasets for training, evaluating, and improving machine learning models. It is a crucial step in natural language processing (NLP) tasks, as it helps algorithms understand, interpret, and make predictions based on textual inputs.
Text annotation is important because it helps bridge the gap between unstructured textual data and structured, machine-readable data. This enables machine learning models to learn and generalize patterns from the annotated examples.
High-quality annotations are vital for building accurate and robust models. This is why careful attention to detail, consistency, and domain expertise is essential in text annotation.
Types of Text Annotation

When training NLP algorithms, it’s essential to have large annotated text datasets tailored to each project’s unique needs. So, for developers who want to create such datasets, here’s a simple overview of five popular text annotation types.

Sentiment Annotation
Sentiment annotation identifies a text’s underlying emotions, opinions, or attitudes. Annotators label textual segments with positive, negative, or neutral sentiment tags. Sentiment analysis, a key application of this annotation type, is widely used in social media monitoring, customer feedback analysis, and market research.

Intent Annotation
Intent annotation aims to capture the purpose or goal behind a given text. In this type of annotation, annotators assign labels to text segments representing specific user intentions, such as asking for information, requesting something, or expressing a preference.

Semantic Annotation
Semantic annotation identifies the meaning and relationships between words, phrases, and sentences. Annotators use various techniques, such as text segmentation, document analysis, and text extraction, to label and classify the semantic properties of text elements.

Entity Annotation
Entity annotation is crucial in creating chatbot training datasets and other NLP data. It involves finding and labeling entities in text. Types of entity annotation include:

Linguistic Annotation
Linguistic annotation deals with the structural and grammatical aspects of language. It encompasses various sub-tasks, such as part-of-speech tagging, syntactic parsing, and morphological analysis.

Relationship Annotation
Relationship annotation identifies and labels connections between different parts of a document. Common tasks include entity linking, relationship extraction, and semantic role labeling. The choice of technique depends on the project's needs.
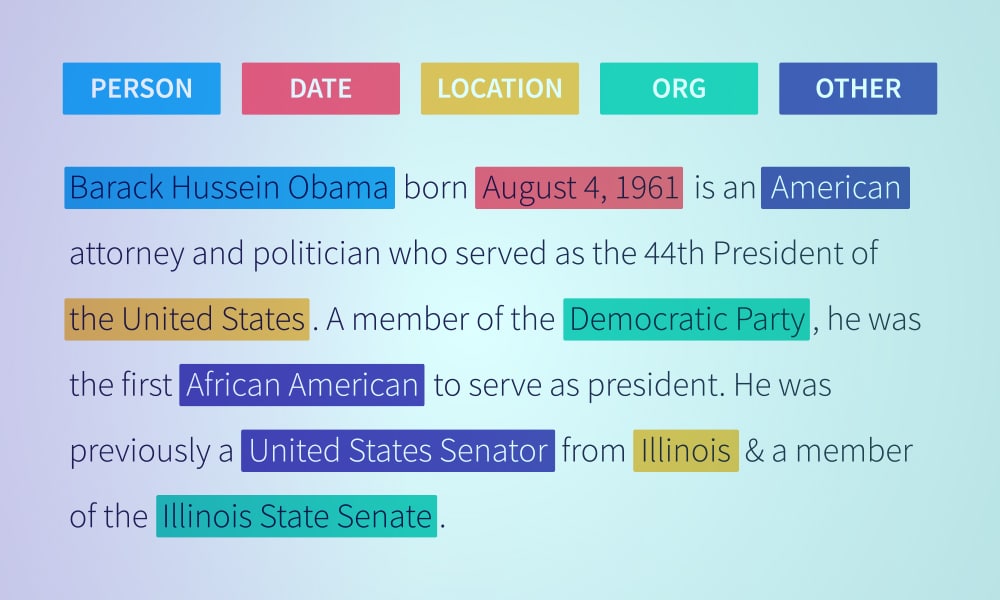
Text Classification
Text classification is all about categorizing text into predefined labels. It’s used for tasks like detecting spam, analyzing sentiment, and identifying topics. The method you choose depends on what you need to achieve.
How To Annotate Text Data?

- Define the annotation task: Determine the specific NLP task you want to address, such as sentiment analysis, named entity recognition, or text classification.
- Choose a suitable annotation tool: Select a text annotation tool or platform that meets your project requirements and supports the desired annotation types.
- Create annotation guidelines: Develop clear and consistent guidelines for annotators to follow, ensuring high-quality and accurate annotations.
- Select and prepare the data: Gather a diverse and representative sample of raw text data for the annotators to work on.
- Train and evaluate annotators: Provide training and continuous feedback to annotators, ensuring consistency and quality in the annotation process.
- Annotate the data: Annotators label the text according to the defined guidelines and annotation types.
- Review and refine annotations: Regularly review and refine the annotations, addressing any inconsistencies or errors and iteratively improving the dataset.
- Split the dataset: Divide the annotated data into training, validation, and testing sets to train and evaluate the machine learning model.
What Can Shaip Do For You?
Shaip offers tailored text annotation solutions to power your AI and machine learning applications in various industries. With a strong focus on high-quality and accurate annotations, Shaip’s experienced team and advanced annotation platform can handle diverse text data.
Whether it’s sentiment analysis, named entity recognition, or text classification, Shaip delivers custom datasets to help enhance your AI models’ language understanding and performance.
Trust Shaip to streamline your text annotation process and ensure your AI systems reach their full potential.







