
Data is the superpower that is transforming the digital landscape in today’s world. From emails to social media posts, there is data everywhere. It is true that businesses have never had access to so much data, but does having access to data enough? The rich source of information becomes useless or obsolete when it is not processed.
Unstructured text can be a rich source of information, but it will not be useful to businesses unless the data is organized, categorized, and analyzed. Unstructured data, such as text, audio, videos, and social media, amounts to 80 -90% of all data. Moreover, barely 18% of organizations are reportedly taking advantage of their organization’s unstructured data.
Manually sifting through terabytes of data stored in the servers is a time-consuming and frankly impossible task. However, with the advancements in machine learning, natural language processing, and automation, it is possible to structure and analyze text data quickly and effectively. The first step in data analysis is text classification.
What is Text Classification?
Text classification or categorization is the process of grouping text into predetermined categories or classes. Using this machine learning approach, any text – documents, web files, studies, legal documents, medical reports, and more – can be classified, organized, and structured.
Text classification is the basic step in natural language processing that has several uses in spam detection. Sentiment analysis, intent detection, data labeling, and more.
Possible Use Cases of Text Classification
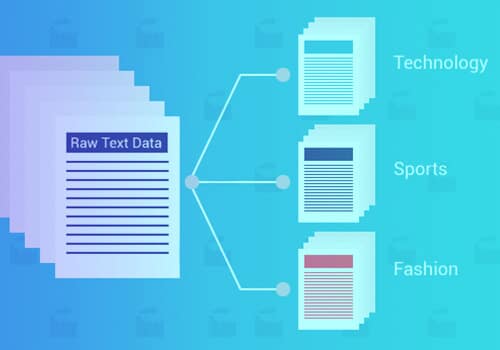 There are several benefits to using machine learning text classification, such as scalability, speed of analysis, consistency, and the ability to make quick decisions based on real-time conversations.
There are several benefits to using machine learning text classification, such as scalability, speed of analysis, consistency, and the ability to make quick decisions based on real-time conversations.
When the ML model is trained on AI that automatically categorizes items under pre-set categories, you can quickly convert casual browsers into customers.
Text Classification Process
The text classification process starts with pre-processing, feature selection, extraction, and classifying data.

Pre-Processing
Tokenization: Text is broken down into smaller and simpler text forms for easy classification.
Normalization: All text in a document needs to be on the same level of comprehension. Some forms of normalization include,
- Maintaining grammatical or structural standards across the text, such as the removal of white spaces or punctuations. Or maintaining lower cases throughout the text.
- Removing prefixes and suffixes from words and bringing them back to their root word.
- Removing stop words such as ‘and’ ‘is’ ‘the’ and more that do not add value to the text.
Feature Selection
Feature selection is a fundamental step in text classification. The process is aimed at representing texts with the most relevant features. Feature selections help remove irrelevant data, and enhance accuracy.
Feature selection reduces the input variable into the model by using only the most relevant data and eliminating noise. Based on the type of solution you seek, your AI models can be designed to choose only the relevant features from the text.
Feature Extraction
Feature extraction is an optional step that some businesses undertake to extract additional key features in the data. Feature extraction uses several techniques, such as mapping, filtering, and clustering. The primary benefit of using feature extraction is – it helps remove redundant data and improve the speed with which the ML model is developed.
Tagging Data to Predetermined Categories
Tagging text to predefined categories is the final step in text classification. It can be done in three different ways,
- Manual Tagging
- Rule-Based Matching
- Learning Algorithms – The learning algorithms can further be classified into two categories such as supervised tagging and unsupervised tagging.
- Supervised learning: The ML model can automatically align the tags with existing categorized data in supervised tagging. When categorized data is already available, the ML algorithms can map the function between the tags and text.
- Unsupervised learning: It happens when there is a dearth of previously existing tagged data. ML models use clustering and rule-based algorithms to group similar texts, such as based on product purchase history, reviews, personal details, and tickets. These broad groups can be further analyzed to draw valuable customer-specific insights that can be used to design tailored customer approaches.
Text Classification: Applications and Use Cases
Autonomizing grouping or classifying large chunks of text or data yields several benefits, giving rise to distinct use cases. Let’s look at some of the most common ones here:
- Spam Detection: Used by email service providers, telecom service providers, and defender apps to identify, filter, and block spam content
- Sentiment Analysis: Analyze reviews and user-generated content for underlying sentiment and context and assist in ORM (Online Reputation Management)
- Intent Detection: Better understand the intent behind prompts or queries provided by users to generate accurate and relevant results
- Topic Labeling: Categorize news articles or user-created posts by predefined subjects or topics
- Language Detection: Detect the language a text is displayed or presented in
- Urgency Detection: Identify and prioritize emergency communications
- Social Media Monitoring: Automate the process of keeping an eye out for social media mentions of brands
- Support Ticket Categorization: Compile, organize, and prioritize support tickets and service requests from customers
- Document Organization: Sort, structure, and standardize legal and medical documents
- Email Filtering: Filter emails based on specific conditions
- Fraud Detection: Detect and flag suspicious activities across transactions
- Market Research: Understand market conditions from analyses and assist in better positioning of products and digital ads and more
What metrics are used to evaluate text Classification?
Like we mentioned, model optimization is inevitable to ensure your model performance is consistently high. Since models can encounter technical glitches and instances like hallucinations, it’s essential that they are passed through rigorous validation techniques before they are taken live or presented to a test audience.
To do this, you can leverage a powerful evaluation technique called Cross-Validation.
Cross-Validation
This involves breaking up training data into smaller chunks. Each small chunk of training data is then used as a sample to train and validate your model. As you kickstart the process, your model trains on the initial small chunk of training data provided and is tested against other smaller chunks. The end results of model performance are weighed against the results generated by your model trained on user-annotated data.
Key Metrics Used In Cross-Validation
| Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|
| which denotes the number of right predictions or results generated concerning total predictions | which denotes the consistency in predicting the right outcomes when compared to the total right predictions | which denotes your model’s ability to predict fewer false positives | which determines the overall model performance by calculating the harmonic mean of recall and precision |
How do you execute text classification?
While it sounds daunting, the process of approaching text classification is systematic and usually involves the following steps:
- Curate a training dataset: The first step is compiling a diverse set of training data to familiarize and teach models to detect words, phrases, patterns, and other connections autonomously. In-depth training models can be built on this foundation.
- Prepare the dataset: The compiled data is now ready. However, it’s still raw and unstructured. This step involves cleaning and standardizing the data to make it machine-ready. Techniques such as annotation and tokenization are followed in this phase.
- Train the text classification model: Once the data is structured, the training phase begins. Models learn from annotated data and start making connections from the fed datasets. As more training data is fed into models, they learn better and autonomously generate optimized results that are aligned to their fundamental intent.
- Evaluate and optimize: The final step is the evaluation, where you compare results generated by your models with pre-identified metrics and benchmarks. Based on results and inferences, you can take a call on whether more training is involved or if the model is ready for the next stage of deployment.
Developing an effective and insightful text classification tool is not easy. Still, with Shaip as your data—partner, you can develop an effective, scalable, and cost-effective AI-based text classification tool. We have tons of accurately annotated and ready-to-use datasets that can be customized for your model’s unique requirements. We turn your text into a competitive advantage; get in touch today.









