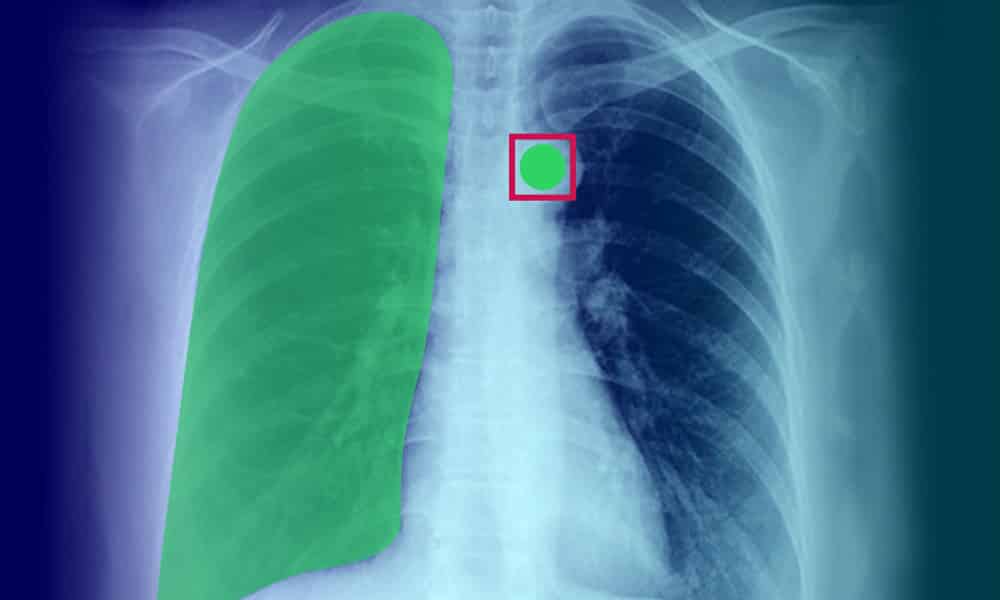
Manual vs. Automated Annotation Quality Review
While auto annotation methods driven by AI can speed up the process, they often require human oversight to avoid errors. Small inaccuracies in data annotation can lead to significant project issues due to AI drift. As a result, many organizations still rely on data scientists to manually review data for inconsistencies and ensure accuracy.
Choosing the Right Data Labeling Vendor for Your AI Project
Outsourcing data labeling is considered an ideal alternative to in-house efforts, as it ensures machine learning developers have on-time access to high-quality data. However, with multiple vendors in the market, selecting the right partner can be challenging. Below are the key steps to choosing the right data labeling vendor:

1. Identify and Define Your Goals
Clear goals act as the foundation for your collaboration with a data labeling vendor. Define your project requirements, including:
- Timelines
- Volume of data
- Budget
- Preferred pricing strategies
- Data security needs
A well-defined Scope of Project (SoP) minimizes confusion and ensures streamlined communication between you and the vendor.
2. Treat Vendors as an Extension of Your Team
Your data labeling vendor should integrate seamlessly into your operations as an extension of your in-house team. Evaluate their familiarity with:
- Your model development and testing methodologies
- Time zones and operational protocols
- Communication standards
This ensures smooth collaboration and alignment with your project goals.
3. Tailored Delivery Modules
AI training data requirements are dynamic. At times, you may need large volumes of data quickly, while at others, smaller datasets over a sustained period suffice. Your vendor should accommodate such changing needs with scalable solutions.
Data Security and Compliance: A Crucial Factor
Data security is paramount when outsourcing annotation tasks. Look for vendors who:
- Adhere to regulatory requirements such as GDPR, HIPAA, or other relevant protocols.
- Implement airtight data confidentiality measures.
- Offer data de-identification processes, especially if you deal with sensitive data like healthcare information.
The Importance of Running a Vendor Trial
Before committing to a vendor, run a short trial project to evaluate:
- Work ethics
- Response times
- Quality of final datasets
- Flexibility
- Operational methodologies
This helps you understand their collaboration methods, identify any red flags, and ensure alignment with your standards.
Pricing Strategies and Transparency
When selecting a vendor, ensure their pricing model aligns with your budget. Ask questions about:
- Whether they charge per task, per project, or by the hour.
- Additional charges for urgent requests or other specific needs.
- Contract terms and conditions.
Transparent pricing reduces the risk of hidden costs and helps scale your requirements as needed.
Avoiding AI Project Pitfalls: Why Partner with an Experienced Vendor
Many organizations struggle with the lack of in-house resources for annotation tasks. Building an in-house team is expensive and time-consuming. Outsourcing to a reliable data labeling vendor like Shaip eliminates these bottlenecks and ensures high-quality outputs.
Why Choose Shaip?
- Fully Managed Workforce: We provide expert annotators for consistent, accurate data labeling.
- Comprehensive Data Services: From sourcing to annotation, we cover the entire process.
- Regulatory Compliance: All data is de-identified and adheres to global standards like GDPR and HIPAA.
- Cloud-Based Tools: Our platform includes proven tools and workflows to improve project efficiency.
Wrapping Up: The Right Vendor Can Accelerate Your AI Project
Accurate data annotation is critical for the success of your AI project, and choosing the right vendor ensures you meet your goals efficiently. By outsourcing to an experienced partner like Shaip, you gain access to a trusted team, scalable solutions, and unmatched data quality.
If you’re ready to simplify your annotation needs and supercharge your AI initiatives, reach out to us today to discuss your requirements or request a demo.