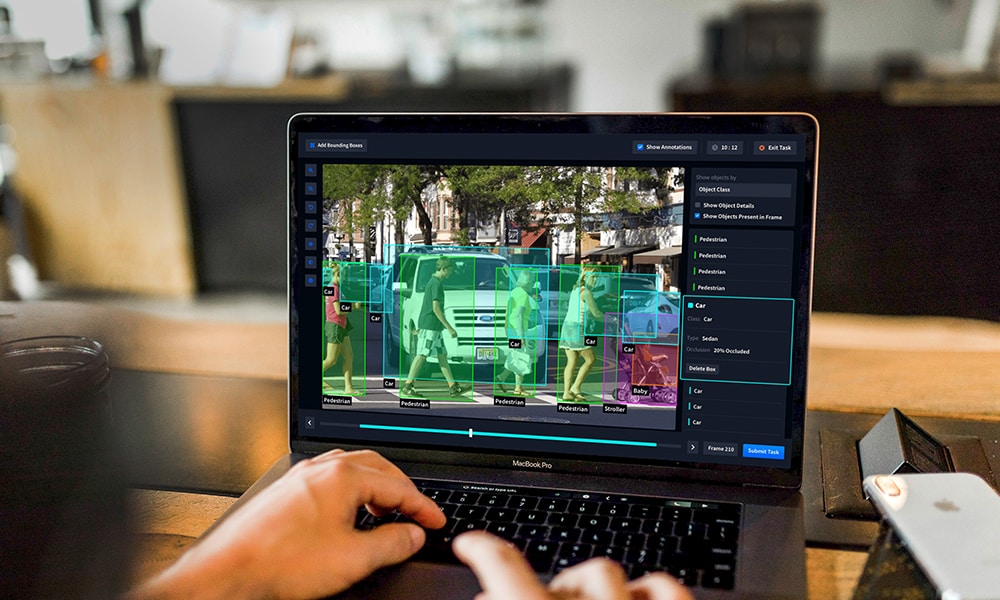
The world is not been the same ever since computers started looking at objects and interpreting them. From entertaining elements that could be as simple as a Snapchat filter that produces a funny beard on your face to complex systems that autonomously detect the presence of minute tumors from scan reports, computer vision is playing a major role in the evolution of humankind.
However, for an untrained AI system, a visual sample or dataset fed into it means nothing. You could feed an image of a bustling Wall Street or an image of ice cream, the system wouldn’t know what both are. That’s because they haven’t learned how to classify and segment images and visual elements yet.
Now, this is a very complex and time-consuming process that requires meticulous attention to detail and labor. This is where data annotation experts come in and manually attribute or tag every single byte of information on images to ensure AI models learn easily the different elements in a visual dataset. When a computer trains on annotated data, it easily differentiates a landscape from a cityscape, an animal from a bird, beverage and food, and other complex classifications.
Now that we know this, how do data annotators classify and tag image elements? Are there any specific techniques they use? If yes, what are they?
Well, this is exactly what this post is going to be about – image annotation types, their advantages, challenges, and use cases.
Image Annotation Types
Image annotation techniques for computer vision can be classified into five major categories:
- Object detection
- Line detection
- Landmark detection
- Segmentation
- Image classification
Object Detection
 As the name suggests, the goal of object detection is to help computers and AI models identify different objects in images. To specify what diverse objects are, data annotation experts deploy three prominent techniques:
As the name suggests, the goal of object detection is to help computers and AI models identify different objects in images. To specify what diverse objects are, data annotation experts deploy three prominent techniques:
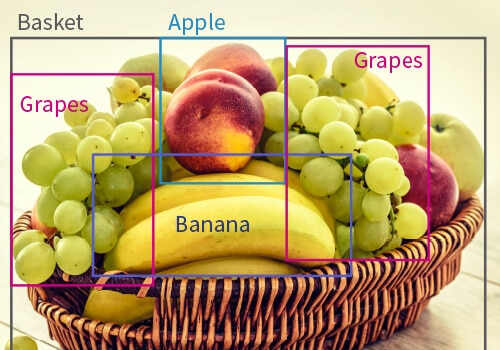
- 2D Bounding Boxes: where rectangular boxes over different objects in images are drawn and labeled.
- 3D Bounding Boxes: where 3-dimensional boxes are drawn over objects to bring out the depth of objects as well.
- Polygons: where irregular and unique objects are labeled by marking edges of an object and ultimately joining them together to cover the shape of the object.
Advantages
- 2D and 3D bounding boxes techniques are very simple and objects can be labeled easily.
- 3D bounding boxes offer more details such as the orientation of an object, which is absent in the 2D bound boxes technique.
Cons Of Object Detection
- 2D and 3D bounding boxes also include background pixels that are actually not part of an object. This skews training in multiple ways.
- In the 3D bounding boxes technique, annotators mostly assume the depth of an object. This also significantly affects training.
- The polygon technique could be time-consuming if an object is very complex.
Line Detection
This technique is used to segment, annotate or identify lines and boundaries in images. For instance, lanes on a city road.
Advantages
The major advantage of this technique is that pixels that don’t share a common border can be detected and annotated as well. This is ideal to annotate lines that are short or those that are occluded.
Disadvantages
- If there are several lines, the process becomes more time-consuming.
- Overlapping lines or objects could give misleading information and results.
Landmark Detection
Landmarks in data annotation don’t mean places of special interests or significance. They are special or essential points in an image that needs to be annotated. This could be facial features, biometrics, or more. This is otherwise known as pose estimation as well.
Advantages
It is ideal to train neural networks that require precise coordinates of landmark points.
Disadvantages
This is very time-consuming as every minute essential point has to be precisely annotated.
Segmentation
A complex process, where a single image is classified into multiple segments for the identification of different aspects in them. This includes detection of boundaries, locating objects, and more. To give you a better idea, here’s a list of prominent segmentation techniques:
- Semantic segmentation: where every single pixel in an image is annotated with detailed information. Crucial for models that require environmental context.
- Instance segmentation: where each and every instance of an element in an image is annotated for granular information.
- Panoptic segmentation: where details from semantic and instance segmentation are included and annotated in images.
Advantages
- These techniques bring out the finest pieces of information from objects.
- They add more context and value for training purposes, ultimately optimizing results.
Disadvantages
These techniques are labor-intensive and tedious.
Image Classification
 Image classification involves the identification of elements in an object and classifying them into specific object classes. This technique is very much different from the object detection technique. In the latter, objects are merely identified. For instance, an image of a cat could be simply annotated as an animal.
Image classification involves the identification of elements in an object and classifying them into specific object classes. This technique is very much different from the object detection technique. In the latter, objects are merely identified. For instance, an image of a cat could be simply annotated as an animal.
However, in image classification, the image is classified as a cat. For images with multiple animals, every animal is detected and classified accordingly.
Advantages
- Gives machines more details on what objects in datasets are.
- Helps models accurately differentiate among animals (for example) or any model-specific element.
Disadvantages
Requires more time for data annotation experts to carefully identify and classify all image elements.
Use Cases of Image Annotation techniques in Computer Vision
| Image Annotation Technique | Use Cases |
|---|---|
| 2D & 3D bounding boxes | Ideal to annotate images of products and goods for machine learning systems to estimate costs, inventory, and more. |
| Polygons | Because of their ability to annotate irregular objects and shapes, they are ideal for tagging human organs in digital imaging records such as X-Rays, CT scans, and more. They can be used to train systems to detect anomalies and deformities from such reports. |
| Semantic Segmentation | Used in the self-driving car’s space, where every pixel associated with vehicle movement can be tagged precisely. Image classification is applicable in self-driving cars, where data from sensors can be used to detect and differentiate among animals, pedestrians, road objects, lanes, and more. |
| Landmark Detection | Used to detect and study human emotions and for the development of facial recognition systems. |
| Lines And Splines | Useful in warehouses and manufacturing units, where boundaries could be established for robots to perform automated tasks. |
Wrapping Up
Like you see, computer vision is extremely complex. There are tons of intricacies that need to be taken care of. While these look and sound daunting, additional challenges include the timely availability of quality data, error-free data annotation processes, and workflows, the subject-matter expertise of annotators, and more.
That being said, data annotation companies such as Shaip are doing a tremendous job of delivering quality datasets to companies that require them. In the coming months, we could also see evolution in this space, where machine learning systems could accurately annotate datasets by themselves with zero errors.