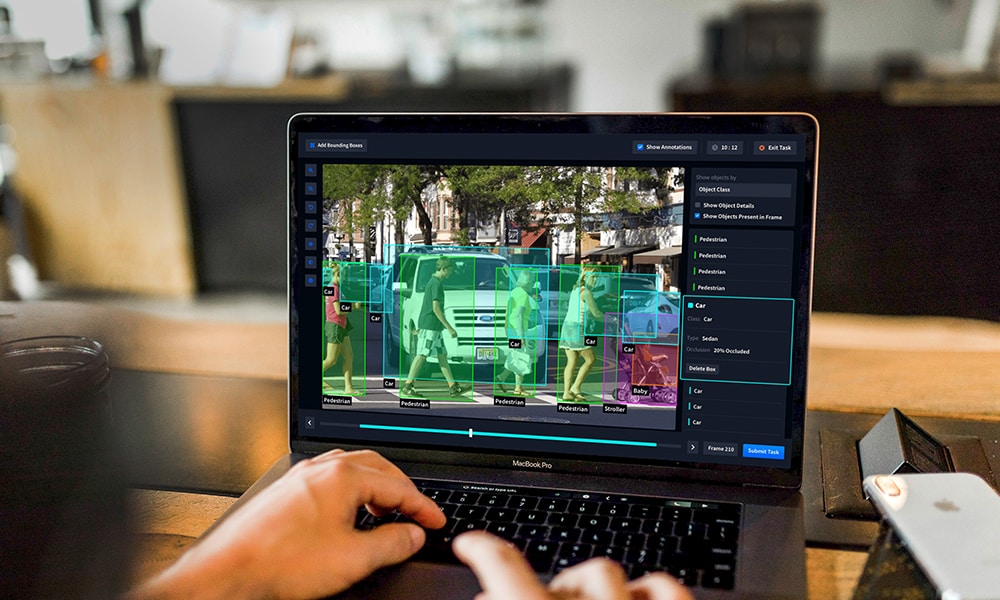
If you’re developing an AI solution, the time-to-market of your product relies heavily on the timely availability of quality datasets for training purposes. Only when you have your required datasets in hand that you initiate your models’ training processes, optimize results and get your solution geared up for launch.
And you know, fetching quality datasets on time is a daunting challenge for businesses of all sizes and scales. For the uninitiated, close to 19% of the businesses reveal that it’s the lack of availability of data that restricts them from adopting AI solutions.
We should also understand that even if you manage to generate relevant and contextual data, data annotation is a challenge by itself. It’s time-consuming and requires excellent mastery and attention to detail. Around 80% of an AI’s development time goes on annotating datasets.
Now, we can’t just completely eliminate data annotation processes from our systems as they are the fulcrum of AI training. Your models would fail to deliver results (let alone quality results) if there are no annotated data in hand. So far, we’ve discussed a myriad of topics on data-based challenges, annotation techniques, and more. Today, we will discuss another crucial aspect that revolves around data labeling itself.
In this post, we will explore the two types of annotation methods used across the spectrum, which are:
- Manual data labeling
- And automatic data labeling
We will shed light on the differences between the two, why manual intervention is key, and what are the risks associated with automatic data labeling.
Manual Data Labeling
As the name suggests, manual data labeling involves humans. Data annotation experts take charge of tagging elements in datasets. By experts, we mean SMEs and domain authorities who know precisely what to annotate. The manual process begins with annotators being provided with raw datasets for annotation. The datasets could be images, video files, audio recordings or transcripts, texts, or a combination of these.
Based on projects, required outcomes, and specifications, annotators work on annotating relevant elements. Experts know what technique is most suitable for specific datasets and purposes. They use the right technique for their projects and deliver trainable datasets on time.
 Manual labeling is extremely time-consuming and the average annotation time per dataset depends on a number of factors such as the tool used, the number of elements to be annotated, quality of data, and more. For instance, it could take up to 1500 hours for an expert to label close to 100,000 images with 5 annotations per image.
Manual labeling is extremely time-consuming and the average annotation time per dataset depends on a number of factors such as the tool used, the number of elements to be annotated, quality of data, and more. For instance, it could take up to 1500 hours for an expert to label close to 100,000 images with 5 annotations per image.
While manual labeling is just one part of the process, there is a second phase in the annotation workflow called quality checks and audits. In this, annotated datasets are verified for authenticity and precision. To do this, companies adopt a consensus method, where multiple annotations work on the same datasets for unanimous outcomes. Discrepancies are resolved in case of comments and flagging as well. When compared to the annotation process, the quality check phase is less strenuous and time-demanding.
Automatic Data Labeling
So, now you understand how much manual effort goes into data labeling. For solutions to be used in sectors like healthcare, precision, and attention to detail becomes all the more crucial. To pave the way for faster data labeling and delivery of annotated data, automatic data labeling models are gradually becoming prominent.
In this method, AI systems take care of annotating data. This is achieved with the help of either heuristic methods or machine learning models or both. In the heuristic method, a single dataset is passed through a series of predefined rules or conditions to validate a specific label. The conditions are laid by humans.
While this is efficient, this method fails when data structures frequently change. Also, laying out conditions becomes complex to drive systems to make an informed decision. While humans can differentiate between ice cream and lemonade, we don’t know the approach the brain takes to come up with the distinction. To replicate this is humanly impossible in machines.
This gives rise to a number of concerns with respect to the quality of results from AI systems. Despite automation kicking in, you need a human (or a bunch of them) to validate and fix data labels. And this is an excellent segue to our next section.
AI-Assisted Annotation: Intelligence Requires Brains (Hybrid Approach)
For the best results, a hybrid approach is required. While AI systems can take care of faster labeling, humans can validate results and optimize them. Leaving the entire process of data annotation in the hands of machines could be a bad idea and that’s why bringing in humans in the loop makes complete sense.
 Once trained, machines can segment and annotate the most fundamental elements precisely. It’s only the complex tasks that require manual intervention. In such cases, this wouldn’t be as time-consuming as manual data labeling and as risky as automatic data labeling.
Once trained, machines can segment and annotate the most fundamental elements precisely. It’s only the complex tasks that require manual intervention. In such cases, this wouldn’t be as time-consuming as manual data labeling and as risky as automatic data labeling.
There is a balance that’s established and the process can happen in cost-effective ways as well. Experts could come up with optimized feedback loops for machines to churn out better labels, ultimately reducing the need for involved manual efforts. With the significant increase in machine confidence scores, the quality of labeled data can be improved as well.
Wrapping Up
Completely autonomous data labeling mechanisms would never work – at least for now. What we require is harmony between man and machines in accomplishing a tedious task. This also increases the delivery time of annotated datasets, where companies can seamlessly initiate their AI training phases. And if you’re looking for high-quality datasets for your AI models, reach out to us today.









