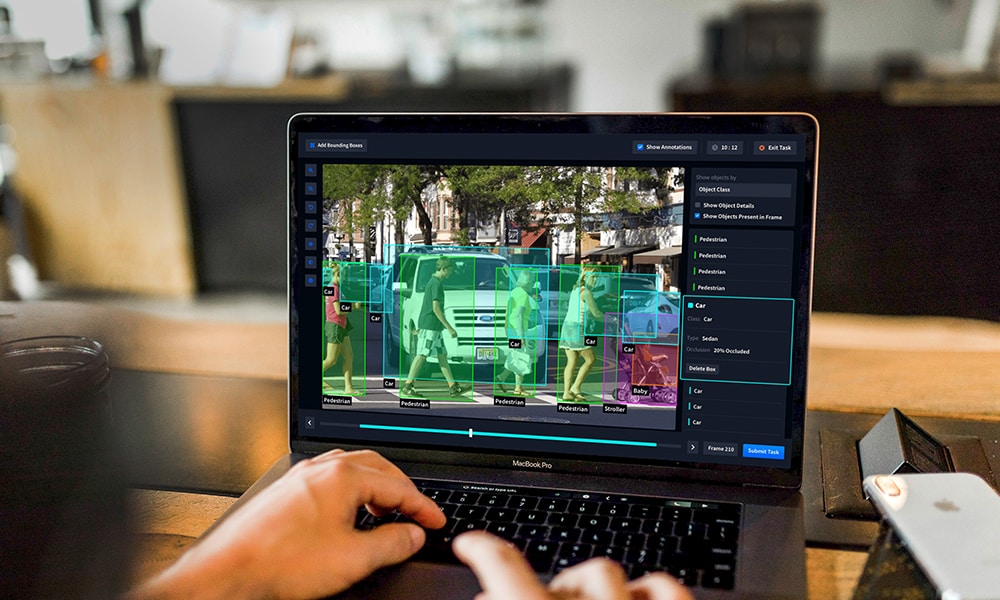
Every ML Engineer wants to develop a reliable and accurate AI model. Data scientists spend nearly 80% of their time labeling and augmenting data. That’s why the model’s performance depends on the quality of the data used to train it.
As we have been catering to the diverse AI project needs of businesses, we come across a few questions that our business clients frequently ask us or require clarity. So we decided to provide a ready reference for how our expert team develops gold-standard training data to train ML models accurately.
Before we navigate the FAQs, let’s lay down some basics of data labeling and its importance.
What is Data Labeling?
Data labeling is the pre-processing step of labeling or tagging data, such as images, audio, or video, to help the ML models and enable them to make accurate predictions.
Data labeling need not be confined to the initial stage of machine learning model development but can continue post-deployment to further improve the accuracy of the predictions.
Data Labeling Importance
 Labeling the data based on the object class, the ML model is trained to identify similar classes of objects – without data tagging – during production.
Labeling the data based on the object class, the ML model is trained to identify similar classes of objects – without data tagging – during production.
Data labeling is a critical pre-processing step that helps build an accurate model that can reliably understand real-world environments. Accurately labeled datasets ensure precise predictions and high-quality algorithms.
Commonly asked questions
Here, as promised, is a ready reference for all the questions you might have and the mistakes you can avoid during any stage of the development lifecycle.
How do you make sense of the data?
As a business, you may have collected a massive amount of data, and now you want to – hopefully – extract key insights or valuable information from the data.
But, without a clear understanding of your project requirements or business objectives, you won’t be able to make practical use of the training data. So don’t begin sifting through your data to find patterns or meaning. Instead, go in with a definite purpose so you don’t find solutions to the wrong problems.
Is the training data a good representative of the production data? If not, how do I identify it?
Although you might not have considered it, the labeled data you are training your model on could be significantly different from the production environment.
How to identify? Look for the tell-tale signs. Your model performed well in a test environment and remarkably less during production.
Solution?
Touch base with the business or domain experts to understand the exact requirements accurately.
-
How to mitigate bias?
The only solution to mitigating bias is to be proactive in eliminating bias before they are introduced into your model.
Data bias could be in any form – from unrepresentative datasets to issues with the feedback loops. Keeping yourself abreast of the latest developments and establishing robust process standards and framework is essential to counter the different forms of bias.
-
How do I prioritize my training data annotation process?
It is one of the most common questions we get asked – which part of the dataset should we prioritize when annotating? It is a valid question, especially when you have large datasets. You don’t have to annotate the entire set.
You can use advanced techniques that help you choose a specific part of your dataset and cluster it so that you send only the required subset of data for annotation. This way, you can send the most crucial information about your model’s success.
-
How do I work around exceptional cases?
Dealing with exceptional cases might be challenging for every ML model. Even though the model might work technically, it might not cut the deal when it comes to serving your business needs.
 Although a vehicle detection model can identify vehicles, it might not be able to differentiate between various types of vehicles reliably. For example – recognizing ambulances from other types of vans. Only when the model can be relied on to identify specific models can the vehicle detection algorithm dictate the safety codes.
Although a vehicle detection model can identify vehicles, it might not be able to differentiate between various types of vehicles reliably. For example – recognizing ambulances from other types of vans. Only when the model can be relied on to identify specific models can the vehicle detection algorithm dictate the safety codes.To counter this challenge, having human-in-the-loop feedback and supervised learning is critical. The solution lies in using similarity search and filtering through the entire dataset to gather similar images. With this, you can focus on annotating only the subset of similar images and enhance it using the human-in-the-loop method.
-
Are there any specific labels that I need to be aware of?
Although you might be tempted to provide the most detail-oriented labeling for your images, it might not always be necessary or ideal. The sheer amount of time and cost it would take to give every image a granular level of detailing and precision is hard to achieve.
Being over-prescriptive or asking for the highest precision in data annotation is suggested when you have clarity on the model requirements.
-
How do you account for edge cases?
Account for edge cases when preparing your data annotation strategy. First, however, you must understand that it is impossible to anticipate every edge case you might come across. Instead, you can choose a variability range and a strategy that can discover edge cases as and when they crop up and address them on time.
-
In what way can I manage data ambiguity?
Ambiguity in the dataset is quite common, and you should know how to deal with it for accurate annotation. For example, an image of a half-ripe apple could be labeled as a green apple or a red apple.
The key to solving such ambiguity has clear-cut instructions from the beginning. First, ensure constant communication between the annotators and the subject matter experts. Have a standard rule in place by anticipating such ambiguity and defining standards that can be implemented across the workforce.
-
Are there any ways to enhance model performance in production?
Since the testing environment and the production data differ, there are bound to be deviations in performance after some time. You cannot expect a model to learn things it wasn’t exposed to during training.
Try to keep the testing data in tune with the changing production data. For example, retrain your model, involve human labelers, enhance the data with more accurate and representative scenarios, and retest and use it in production.
-
Whom do I approach for my annotation of training data needs?
Every business has something to gain from developing ML models. Not every business entity is equipped with technical know-how or expert data labeling teams to transform raw data into valuable insight. You should be able to use it to gain a competitive advantage.
While there are aspects, you might be looking for in a data training partner, reliability, experience, and subject knowledge are some of the top three points to remember. Consider these before going in for a reliable third-party service provider.
Leading the list of accurate and reliable data labeling service providers is Shaip. We use advanced analytics, experience teams, and subject matter experts for all your labeling and data annotation needs. Moreover, we follow a standard procedure that has helped us develop top-end annotation and labeling projects for leading businesses.