In our digital world, businesses process tons of data daily. Data keeps the organization running and helps it make better-informed decisions. Businesses are flooded with documents, from employees creating new ones to documents entering the organization from various sources such as emails, portals, invoices, receipts, applications, proposals, claims, and more.
Unless someone reviews these documents, there is no way to know what a particular document is about or the best way to process it. However, manually processing each document to know where and how it should be stored is difficult.
Let us explore document classification, understand why document classification is crucial for a business, and study how Computer Vision, Natural Language Processing, and Optical Character Recognition play a part in Document Classification or Document Processing.
What is Document Classification?
Manual document classification tasks can be a huge bottleneck for many businesses as they are time-consuming, error-prone, and resource-consuming. When automatic classification models based on NLP and ML are used, the text in a document is identified, tagged, and categorized automatically.
Document classification tasks are generally based on two classifications: text and visual. Text classification is based on the content’s genre, theme, or type. Natural Language Processing is used to understand the text’s concept, emotions, and context. Visual classification is done based on the visual structural elements present in the document using Computer Vision and image recognition systems.
Why do businesses require Document Classification?

Every organization, from startups to Fortune 500 companies, deals with vast volumes of documents daily. Without automation, manual document processing becomes a bottleneck that slows down workflows and drains resources.
Here’s why AI-powered document classification is a must-have:
- Accelerates Document Management: Automates sorting, indexing, and routing, enabling instant access to relevant documents.
- Boosts Accuracy & Reduces Errors: Minimizes human mistakes common in repetitive tasks, ensuring data integrity.
- Enhances Operational Efficiency: Frees employees from mundane tasks, allowing focus on strategic initiatives.
- Scales Seamlessly: Handles growing document volumes without proportional increases in staffing.
- Supports Compliance & Security: Ensures sensitive documents are correctly identified and handled according to regulations.
Industries such as healthcare, finance, insurance, legal, and eCommerce are already leveraging AI-based classification to streamline claims processing, contract management, customer support, and inventory categorization.
Document Classification Vs. Text Classification: Understanding the Nuances
While often used interchangeably, document classification and text classification have subtle but important differences:
| Aspect | Text Classification | Document Classification |
|---|---|---|
| Scope | Focuses solely on analyzing and categorizing text. | Analyzes both text and visual/layout elements. |
| Data Input | Purely textual content (sentences, paragraphs). | Entire document including images, tables, formatting. |
| Use Cases | Sentiment analysis, topic tagging, spam detection. | Invoice sorting, contract type identification, form processing. |
| Techniques | NLP-centric methods like sentiment analysis, entity recognition. | Combines NLP with Computer Vision and OCR. |
In essence, text classification is a subset of document classification, which offers a richer, multi-modal understanding of documents.
How does Document Classification work?
Document classification can be done using two methods: manual and automatic. In manual classification, a human user must review documents, find relationships between concepts, and categorize accordingly. In automatic document classification, machine learning and deep learning techniques are used. Let’s unravel document classification methods by understanding the different types of documents a business processes.
Structured Documents
A document contains well-formatted data with consistent numbering and fonts. The layout of the document is also consistent and doesn’t have deviations. Building classification tools for such structured documents is easy and predictable.
Unstructured Documents
An unstructured document has contents presented in a non-structured or open format. Examples include letters, contracts, and orders. Since they are inconsistent, it becomes challenging to locate critical information. 
Document Classification Techniques?
Automatic document classification uses Machine Learning and Natural Language Processing techniques to simplify, automate, and speed up the categorization process. Machine learning makes document classification less cumbersome, faster, more accurate, scalable, and unbiased.
Document classification can be done using three techniques. They are
Rule-Based Technique
The rule-based technique is based on linguistic patterns and rules that provide instructions to the model. The models are trained to identify language patterns, morphology, syntax, semantics, and more to tag the text. This technique can be constantly improved, new rules added and improvised to extract accurate insights. However, this technique can be time-consuming, unscalable, and complex.
Supervised Learning
A set of tags is defined in supervised learning, and several texts are manually tagged so that the machine learning system can learn to make accurate predictions. The algorithm is manually trained on a set of tagged documents. The more data you feed into the system, the better the outcome. For example, if the text says, ‘The service was affordable,’ the tag should be under ‘pricing.’ Once the model’s training is complete, it can automatically predict unseen documents.
Unsupervised Learning
In unsupervised learning, similar documents are grouped into different clusters. This learning does not necessitate any prior knowledge. The documents are categorized based on fonts, themes, templates, and more. If the rules are pre-defined, tweaked, and perfected, this model can deliver classification with accuracy.
How Does AI-Based Document Classification Work?
AI-driven document classification typically follows these key steps:
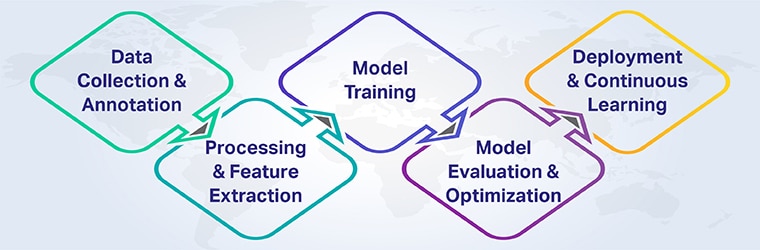
1. Data Collection & Annotation
High-quality, diverse datasets are foundational. Documents must be gathered across categories and accurately labeled (tagged) to train machine learning models effectively.
2. Preprocessing & Feature Extraction
Using Optical Character Recognition (OCR), text is extracted from scanned or image-based documents. NLP techniques then clean, tokenize, and transform the text into meaningful features. Simultaneously, Computer Vision analyzes document layouts and visual cues.
3. Model Training
Supervised learning algorithms (e.g., transformers, CNNs) are trained on labeled data to recognize patterns. Models learn to associate document characteristics with categories.
4. Model Evaluation & Optimization
Models are rigorously tested on unseen data to measure accuracy, precision, and recall. Hyperparameters are tuned to improve performance.
5. Deployment & Continuous Learning
Once deployed, models classify incoming documents in real-time and improve over time through feedback loops and additional training data.
Real-life use cases
Document classification is being used to address several business problems. Although most use cases are not classification tasks, the algorithm finds itself employed to solve several real-life problems.
Spam Detection
Document classification, particularly text classification, is used to detect unwanted spam. The model is trained to detect spam phrases and their frequency to determine if the message is spam. For example, Google’s Gmail Spam detector uses the Natural Language Processing technique to detect frequently occurring words in junk messages and drop the mail in the correct folder.
Sentiment Analysis
Sentiment analysis through social listening helps businesses understand their customers, their opinions, and their reviews. By classifying reviews, feedback, and complaints and categorizing them based on their emotional nature, the NLP-based models help in sentiment analysis. The model is trained to extract words that denote or have positive or negative connotations.
Ticket or Priority Classification
Any business’s customer service department comes across many service requests and tickets. An automated document classification tool can help wade through the massive volume of tickets. Using NLP, priority tickets can be routed to the correct department. This significantly improves the speed of resolution, processing, and servicing.
Object Recognition
Automated document classification is also used to process large amounts of visual data in documents by classifying them according to categories. Object recognition is typically used in eCommerce or manufacturing units to classify products.
Getting Started with Document Classification Powered by AI
Documents contain data critical to the business’s functioning. The documents contain valuable insights that further the operations, services, and growth goals of an organization.
However, classifying documents is a tedious yet necessary task. Since document classification is a challenge, especially if the volume is relatively high, it is necessary to have an automated document classification system.
An AI-based document classification model trained by machine learning algorithms is efficient, cost-effective, error-free, and accurate. But the process can kick off only when the model you are building is trained on quality and accurately tagged datasets.
Shaip brings to you pre-tagged datasets that aid in developing accurate classification models. Get in touch with us and get started with your document classification tool right away.