
Introduction

Artificial intelligence (AI) is now part of everyday work—powering chatbots, copilots, and multimodal tools that handle text, images, and audio. Adoption is accelerating: McKinsey reports 88% of organizations use AI in at least one business function. Market growth is rising too, with one estimate valuing AI at ~$390.9B in 2025 and projecting ~$3.5T by 2033.
Behind every strong AI system is the same foundation: high-quality data. This guide explains how to collect the right data, maintain quality and compliance, and choose the best approach (in-house, outsourced, or hybrid) for your AI projects.
What is AI Data Collection?
AI data collection is the process of building datasets that are ready for model training and evaluation—by sourcing the right signals, cleaning and structuring them, adding metadata, and labeling where required. It’s not just “getting data.” It’s ensuring the data is relevant, reliable, diverse enough for real-world usage, and documented well enough to audit later.
Most Common Data Formats for AI Projects
AI datasets typically fall into four major categories, depending on the system you’re building:
- Text Data: Text is one of the most widely used forms of training data. It can be structured (tables, databases, CRM records, forms) or unstructured (emails, chat logs, surveys, documents, social media comments). For LLMs and chatbots, text data often includes knowledge-base articles, support tickets, and question–answer pairs.
- Audio Data: Audio data helps train and improve speech systems like voice assistants, call analytics, and voice-based chatbots. These datasets capture real-world variation such as accents, pronunciation, background noise, and different ways people ask the same question. Common examples include call center recordings, voice commands, and multilingual speech samples.
- Image Data: Image datasets power computer vision use cases like object detection, medical imaging analysis, retail product recognition, and ID verification. Images often require labels such as tags, bounding boxes, or segmentation masks so models can learn what they’re seeing.
- Video Data: Video is essentially a sequence of images over time, making it useful for deeper understanding of movement and context. Video datasets support applications such as autonomous driving, surveillance analytics, sports analysis, and industrial safety monitoring—often requiring frame-by-frame labeling or event tagging.
In 2026, AI data collection looks different because so many systems are powered by LLM chatbots, RAG (retrieval-augmented generation), and multimodal models. That means teams collect three kinds of data in parallel: learning data (to teach behavior), grounding data (RAG-ready documents for accurate answers), and evaluation data (to measure retrieval accuracy, hallucinations, and policy alignment).

Types of AI Data Collection Methods

1. First-Party (Internal) Data Collection
Data collected from your own product, users, and operations—usually the most valuable because it reflects real behavior.
Example: Exporting support tickets, search logs, and chatbot conversations (with consent), then organizing them by issue type to improve an LLM support assistant.
2. Manual/Expert-Led Collection
Humans deliberately gather or create data when deep context, domain knowledge, or high accuracy is required.
Example: Clinicians reviewing medical reports and labeling key findings to train a healthcare NLP model.
3. Crowdsourcing (Distributed Human Workforce)
Using a large pool of workers to collect or label data quickly at scale. Quality is maintained using clear guidelines, multiple reviewers, and test questions.
Example: Crowd workers transcribe thousands of short audio clips for speech recognition, with “gold” test clips to check accuracy.
4. Web Data Collection (Scraping)
Automatically extracting information from public websites at scale (only when permitted by terms and laws). This data often needs heavy cleaning.
Example: Collecting public product specifications from manufacturer pages and converting messy web content into structured fields for a product-matching model.
5. API-Based Data Collection
Pulling data via official APIs, which usually provide more consistent, reliable, and structured data than scraping.
Example: Using a financial market API to collect price/time-series data for forecasting or anomaly detection.
6. Sensors & IoT Data Collection
Capturing continuous streams from devices and sensors (temperature, vibration, GPS, camera, etc.), often for real-time decisions.
Example: Collecting vibration and temperature signals from factory machines, then using maintenance logs as labels for predictive maintenance.
7. Third-Party/Licensed Datasets
Buying or licensing ready-made datasets from vendors or marketplaces to speed up development or fill coverage gaps.
Example: Licensing a multilingual speech dataset to launch a voice product, then adding first-party recordings to improve performance for your users.
8. Synthetic Data Generation
Creating artificial data to handle privacy constraints, rare events, or class imbalance. Synthetic data should be validated against real-world patterns.
Example: Generating rare fraud transaction patterns to improve detection when real fraud examples are limited.

Data Collection Process: From Requirements to Model-Ready Datasets
A scalable AI data collection process is repeatable, measurable, and compliant—not a one-time dump of raw files. For most AI/ML initiatives, the end goal is clear: a machine-ready dataset that teams can reliably reuse, audit, and improve over time.
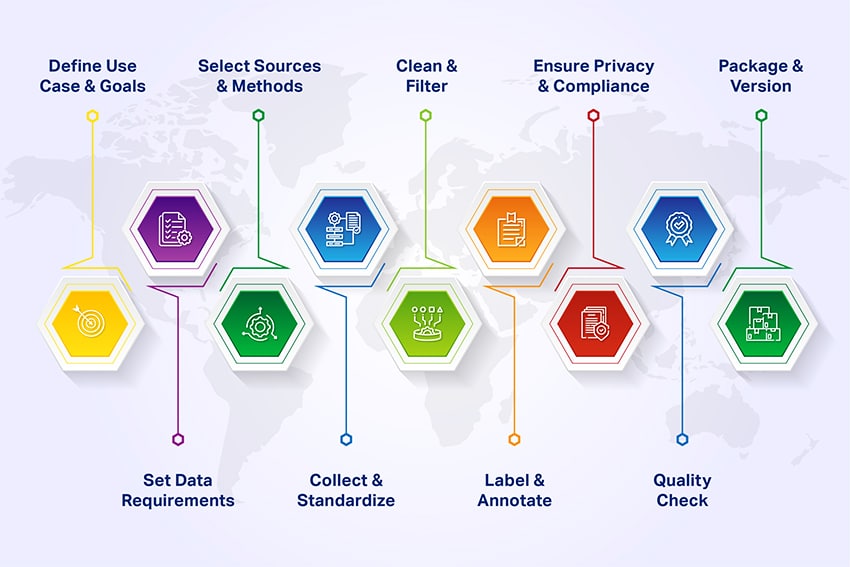
1. Define the Use Case and Success Metrics
Start with the business problem, not the data.
- What problem is this model solving?
- How will success be measured in production?
Examples:
- “Reduce support escalations by 15% over 6 months.”
- “Improve retrieval precision for top 50 self-service queries.”
- “Increase defect detection recall in manufacturing by 10%.”
These targets later drive data volume, coverage, and quality thresholds.
2. Specify Data Requirements
Translate the use case into concrete data specs.
- Data types: text, audio, image, video, tabular, or a mix
- Volume ranges: initial pilot vs. full rollout (e.g., 10K → 100K+ samples)
- Languages and locales: multilingual, accents, dialects, regional formats
- Environments: quiet vs. noisy, clinical vs. consumer, factory vs. office
- Edge cases: rare but high-impact scenarios you cannot afford to miss
This “data requirement spec” becomes the single source of truth for both internal teams and external data vendors.
3. Choose Collection Methods and Sources
At this stage, you decide where your data will come from. Typically, teams combine three main sources:
- Free/Public Datasets: useful for experimentation and benchmarking, but often misaligned with your domain, licensing needs, or timelines.
- Internal Data: CRM, support tickets, logs, medical records, product usage data—highly relevant, but may be raw, sparse, or sensitive.
- Paid/Licensed Data vendors: best when you need domain-specific, high-quality, annotated, and compliant datasets at scale.
Most successful projects mix these:
- Use public data for prototyping.
- Use internal data for domain relevance.
- Use vendors like Shaip when you need scale, diversity, compliance, and expert annotation without overloading internal teams.
Synthetic data can also complement real-world data in some scenarios (e.g., rare events, controlled variations), but should not completely replace real data.
4. Collect and Standardize Data
As data starts flowing in, standardization prevents chaos later.
- Enforce consistent file formats (e.g., WAV for audio, JSON for metadata, DICOM for imaging).
- Capture rich metadata: date/time, locale, device, channel, environment, consent status, and source.
- Align on schema and ontology: how labels, classes, intents, and entities are named and structured.
This is where a good vendor will deliver data in your preferred schema, rather than pushing raw, heterogeneous files to your teams.
5. Clean and Filter
Raw data is messy. Cleaning ensures that only useful, usable, and legal data moves forward.
Typical actions include:
- Removing duplicates and near-duplicates
- Excluding corrupted, low-quality, or incomplete samples
- Filtering out-of-scope content (wrong language, wrong domain, wrong intent)
- Normalizing formats (text encoding, sampling rates, resolutions)
Cleaning is often where internal teams underestimate the effort. Outsourcing this step to a specialized provider can significantly reduce time-to-market.
6. Label and Annotate (when required)
Supervised and human-in-the-loop systems require consistent, high-quality labels.
Depending on the use case, this may include:
- Intents and entities for chatbots and virtual assistants
- Transcripts and speaker labels for speech and call analytics
- Bounding boxes, polygons, or segmentation masks for computer vision
- Relevance judgments and ranking labels for search and RAG systems
- ICD codes, medications, and clinical concepts for healthcare NLP
Key success factors:
- Clear, detailed annotation guidelines
- Training for annotators and access to subject matter experts
- Consensus rules for ambiguous cases
- Measurement of inter-annotator agreement to track consistency
For specialized domains like healthcare or finance, generic crowd annotation is not enough. You need SMEs and audited workflows—exactly where a partner like Shaip brings value.
7. Apply privacy, security, and compliance controls
Data collection must respect regulatory and ethical boundaries from day one.
Typical controls include:
- De-identification/anonymization of personal and sensitive data
- Consent tracking and data usage restrictions
- Retention and deletion policies
- Role-based access controls and data encryption
- Adherence to standards like GDPR, HIPAA, CCPA, and industry-specific regulations
An experienced data partner will bake these requirements into collection, annotation, delivery, and storage, not treat them as an afterthought.
8. Quality Assurance and Acceptance Testing
Before a dataset is declared “model-ready,” it should pass through structured QA.
Common practices:
- Sampling and audits: human review of random samples from each batch
- Gold sets: a small, expert-labeled reference set used to evaluate annotator performance
- Defect tracking: classification of issues (wrong label, missing label, formatting error, bias, etc.)
- Acceptance criteria: pre-defined thresholds for accuracy, coverage, and consistency
Only when a dataset meets these criteria should it be promoted to training, validation, or evaluation.
9. Package, Document, and Version for Reuse
Finally, data must be usable today and reproducible tomorrow.
Best practices:
- Package data with clear schemas, label taxonomies, and metadata definitions
- Include documentation: data sources, collection methods, known limitations, and intended use.
- Version datasets so teams can track which version was used for which model, experiment, or release.
- Make datasets discoverable internally (and securely) to avoid shadow datasets and duplicated effort.
How to Evaluate AI Data Collection Vendors
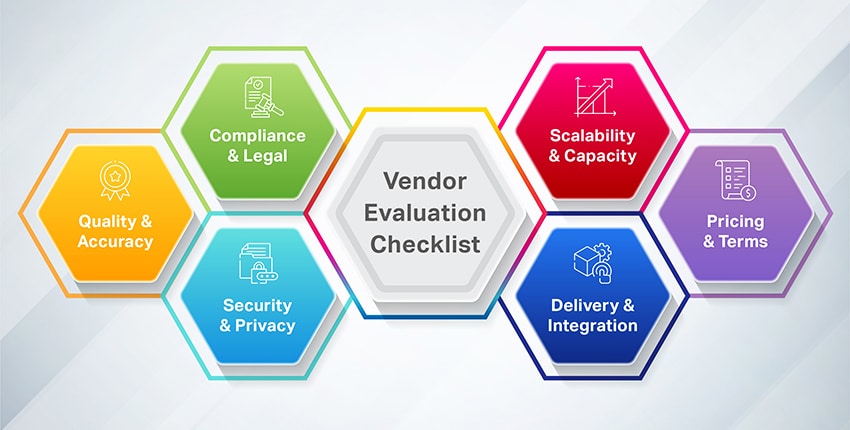
Vendor Evaluation Checklist
Use this checklist during vendor assessments:
Quality & Accuracy
- Documented quality assurance process (multi-tier review, automated checks)
- Inter-annotator agreement metrics available
- Error correction and feedback loop processes
- Sample data review before commitment
Compliance & Legal
- Clear data provenance documentation
- Consent mechanisms for data subjects
- GDPR, CCPA, and relevant regional compliance
- Data licensing terms that cover your intended use
- Indemnification clauses for data IP issues
Security & Privacy
- SOC 2 Type II certification (or equivalent)
- Data encryption at rest and in transit
- Access controls and audit logging
- De-identification and PII handling procedures
- Data retention and deletion policies
Scalability & Capacity
- Proven track record at your required scale
- Surge capacity for time-sensitive projects
- Multi-language and multi-region capabilities
- Workforce depth in your target domains
Delivery & Integration
- API access or automated delivery options
- Compatibility with your ML pipeline (format, schema)
- Clear SLAs with remediation procedures
- Transparent project management and communication
Pricing & Terms
- Transparent pricing model (per-unit, per-hour, project-based)
- No hidden fees for revisions, format changes, or rush delivery
- Flexible contract terms (pilot options, scalable commitments)
- Clear ownership of deliverables
Vendor Scoring Rubric
Use this template to compare vendors systematically: