
Artificial Intelligence (AI) is changing how we solve problems in every industry, from healthcare to banking. However, one big challenge remains: bias in AI systems. This happens when the data used to train AI isn’t diverse enough. Without a wide variety of data, AI can make unfair decisions, exclude certain groups, or give inaccurate results.
To make AI smarter, fairer, and more effective, we must focus on diverse training data. In this blog, we’ll explain why data diversity matters, how it helps eliminate bias, and the steps you can take to create better AI systems.
Why Does Diversity in Training Data Matter?
Training data is what teaches AI models how to work. If the data is limited or one-sided, the AI will only learn from that narrow perspective. This can lead to problems like biased decisions or poor performance in real-world situations. Here’s why diverse data is so important:
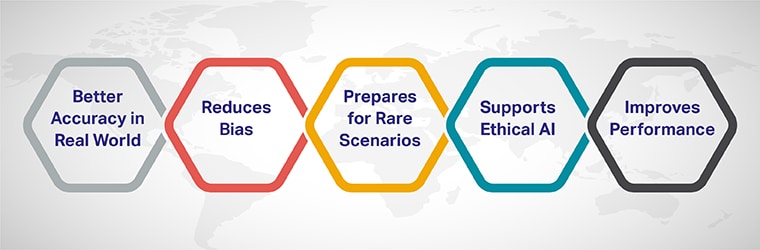
1. Better Accuracy in the Real World
AI models that are trained on a variety of data can handle different situations better. For example, a voice assistant trained on voices of all ages, accents, and genders will work for more people compared to one trained on just a few voices.
2. Reduces Bias
Without diversity, AI can pick up and amplify biases in the data. For instance, if a hiring algorithm is trained only on resumes from men, it might unfairly favor them over equally qualified women. Including data from all groups ensures fairer results.
3. Prepares for Rare Scenarios
Diverse datasets include rare or unique cases that AI may encounter. For example, self-driving cars need to be trained on all kinds of road conditions, including unusual ones like flooded streets or potholes.
4. Supports Ethical AI
AI is used in areas like healthcare and criminal justice, where fairness and ethics are critical. Diverse training data ensures that AI makes decisions that are fair to everyone, regardless of their background.
5. Improves Performance
When AI learns from diverse data, it becomes better at recognizing patterns and making accurate predictions. This leads to smarter, more reliable systems.

The Current Problem with Training Data
Right now, many AI systems fail because their training data isn’t diverse enough. Examples include facial recognition systems that don’t recognize darker skin tones or chatbots that give offensive answers. These failures show why we need to focus on including more diverse data during the AI training process.
How to Make Training Data More Diverse
Creating diverse training data takes effort, but it’s possible with the right strategies. Here’s how you can ensure your data is inclusive and balanced:
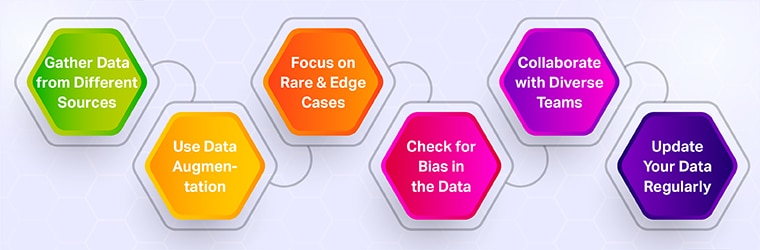
1. Gather Data from Different Sources
Don’t rely on just one source of data. Collect information from different regions, age groups, genders, and ethnicities. For example, if you’re building a language model, include text from various cultures and languages.
2. Use Data Augmentation
Data augmentation is a method to create new data from existing data. For example, you can flip, rotate, or adjust images to create more variety without collecting additional data.
3. Focus on Rare and Edge Cases
Include examples of rare situations in your training data. For instance, if you’re training a healthcare AI, include data from patients with rare conditions to make the model more comprehensive.
4. Check for Bias in the Data
Before using a dataset, review it to ensure it doesn’t favor or exclude any group. For example, if you’re training facial recognition software, make sure the dataset includes faces of all skin tones and genders.
5. Collaborate with Diverse Teams
Work with people from different backgrounds to help identify gaps in your data. A diverse team can bring unique perspectives and ensure fairness in AI development.
6. Update Your Data Regularly
The world changes over time, and so should your data. Regularly update your training data to reflect new trends, technologies, and societal changes.
[Also Read: What Is Training Data in Machine Learning]
Challenges in Ensuring Data Diversity
While diverse training data is essential, it’s not always easy to achieve. Here are some common challenges:
- High Costs: Collecting and labeling diverse data can be expensive and time-consuming.
- Legal Restrictions: Different countries have laws about how data can be collected and used, like the GDPR in Europe.
- Data Gaps: In some cases, it’s hard to find data for under-represented groups or rare scenarios.
To overcome these challenges, you’ll need a thoughtful plan and collaboration with experts.
Building Ethical & Inclusive AI
At its core, AI should help everyone, not just a select few. By focusing on diverse training data, we can create systems that are smarter, fairer, and more inclusive. This isn’t just a technical goal. It’s a responsibility to ensure AI benefits society as a whole.
How Shaip Can Help
At Shaip, we specialize in providing high-quality, diverse datasets tailored to your specific AI needs. Whether you’re building a healthcare app, a chatbot, or a facial recognition system, we can help you create inclusive and reliable AI solutions.
Let’s Build Smarter AI Together!
Contact us today to discuss your training data needs. Together, we can make AI fairer, smarter, and more impactful.









