
Most robotics models work flawlessly in the demo and fall apart in deployment. The reason is almost never the architecture — it’s the data. A policy trained on staged tabletops and predictable objects collapses the moment it sees a cluttered apartment or a real warehouse aisle. Closing that gap is what robot training data and robot manipulation datasets are really for: capturing the messy, multimodal, episode-level signal that lets a robot generalize from a lab to a living room.
Key Takeaways
- Robot training data is time-synchronized, multimodal data combining vision, sensor, and action streams.
- Robot manipulation datasets are the contact-rich subset that teach grasping, placing, and assembly.
- Robotics data pipelines combine crowdsourced diversity with onsite precision — neither alone is enough.
- Annotation spans frame-level labeling, temporal event tagging, and task-execution scoring.
- Robotics data, unlike LLM data, demands human-in-the-loop QA with physical intuition.
What is robot training data?
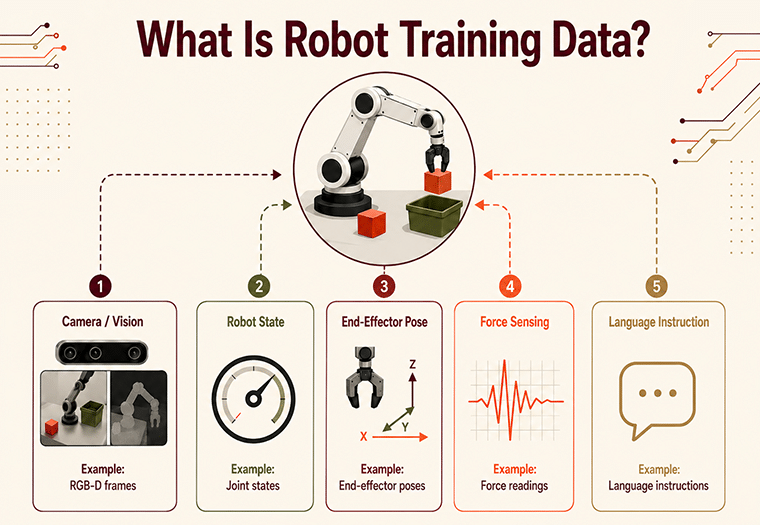
Robot training data is time-synchronized, multimodal data combining vision, sensor, and action streams used to train robotic perception and control models. Every episode pairs what the robot saw with what the robot did — RGB-D frames, joint states, end-effector poses, force readings, and language instructions captured at common timestamps.
Teleoperation data: Robot demonstration data collected when a human operator remotely controls the robot through a task using a leader arm, VR controller, or motion-capture rig.
This temporal pairing is what makes data trainable as a policy. Without it, you have video — useful for perception, useless for control.
How are robot manipulation datasets different from general robot training data?
Robot manipulation dataset: A structured collection of robot trajectories capturing object interactions like grasping, placing, assembling, or tool use, with synchronized observations and actions per timestep.
General robot training data spans everything a robot might do — navigation, locomotion, perception. Manipulation datasets zoom in on the contact-rich, dexterous slice that’s still unsolved. Cross-embodiment data pools demonstrations across different robot platforms to improve how well a policy transfers to new hardware.
What types of robot training data fuel modern robotics models?
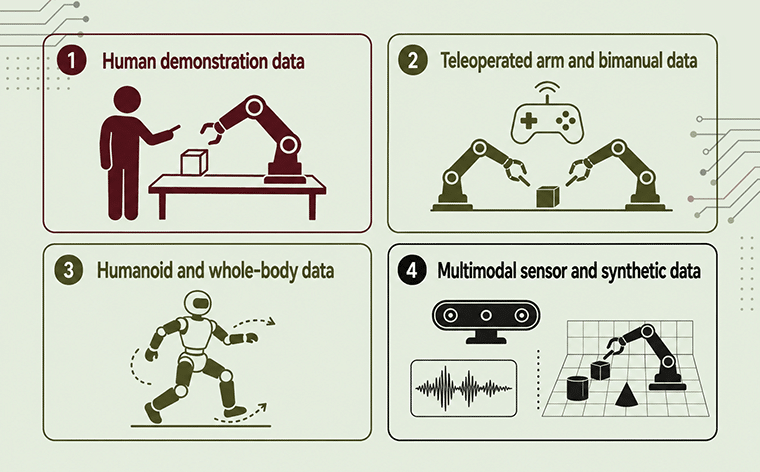
Human demonstration data
First-person video of humans performing everyday tasks — folding laundry, pouring liquids, opening jars — captured with head-mounted cameras and wearable IMUs. Used heavily for pretraining and tasks where direct robot capture is impractical.
Teleoperated arm and bimanual data
The gold standard for manipulation. A human operator drives the robot through demonstrations using a leader arm or VR rig. Bimanual data (two arms coordinating) remains the scarcest and most valuable subtype.
Humanoid and whole-body data
Captured from humanoid platforms performing locomotion plus manipulation simultaneously. Sources include motion-capture suits, exoskeletons, and full-body teleoperation — the fastest-growing data category in 2026.
Multimodal sensor and synthetic data
Vision alone is insufficient. Modern manipulation datasets layer tactile readings, force-torque sensing, audio, depth, and proprioception. Synthetic data from simulators augments real capture for dangerous, rare, or geometrically extreme scenarios.
Crowdsourced vs onsite: how is robot manipulation data actually collected?

Robot manipulation data collection splits into two complementary methods, and production teams use both.
Crowdsourced collection recruits contributors across geographies and demographics to perform familiar tasks — cleaning, organizing, cooking — in their own homes with their own objects. The instruction reads “record yourself tidying your living room,” not “perform manipulation sequence 4B.” The output isn’t pristine, but it’s representative. Diversity is the signal, and it’s what helps policies survive contact with the real world.
Onsite professional collection happens in controlled studios or mock environments with calibrated equipment and trained operators. Variables are pinned: lighting between 10 and 4,000 lux, camera distances from 3 to 20 feet, defined face orientations, scripted task pacing. The trade-off is intentional — give up unpredictability to gain consistency where fine distinctions matter.
Picture a mid-size warehouse robotics team building a bin-picking policy for cluttered shelves. Public datasets cover clean tabletops. Production faces shrink-wrap, varying lighting, and 4,000 SKUs.
Shaip’s Physical AI data collection workflows close that gap by combining crowdsourced demographic breadth with onsite precision capture — the exact mix that public sets alone can’t deliver.
How are robot manipulation datasets annotated?
Raw teleoperation footage isn’t training data until it’s labeled. Three annotation methods dominate robotics pipelines.
Stop-motion sequence labeling
Stop-motion sequence labeling extracts frames at set intervals and labels each one with bounding boxes, class hierarchies, and object states. It’s how models learn that a hand is about to grasp an object versus already holding it. Used heavily for perception, manipulation state detection, and LiDAR point-cloud annotation where three-dimensional geometry matters.
Temporal video annotation
Temporal annotation marks start and end timestamps for each event in continuous footage, paired with contextual descriptions. A two-minute home video produces a structured timeline: 00:00–00:15 reading, 00:15–00:28 petting the cat, 00:28–01:54 reading again. The output trains activity-recognition and task-segmentation models.
Task execution evaluation
Task execution evaluation: Scoring recorded demonstrations against predefined success criteria so teams can identify high-quality training examples and recurring failure patterns. Each step in a demonstration is rated for success, helpfulness, and notes — picking up the spoon (✓), placing in the correct drawer (✓), dropping the fork (✗). Aggregated across thousands of episodes, these scores drive reward modeling and curriculum design for reinforcement learning.
Shaip’s annotation workflows apply all three methods through multi-pass review pipelines, with each pass targeting a different quality dimension — spatial accuracy, temporal consistency, or task-success criteria — depending on the model’s goals.
Why does robotics AI need human-in-the-loop quality assurance?
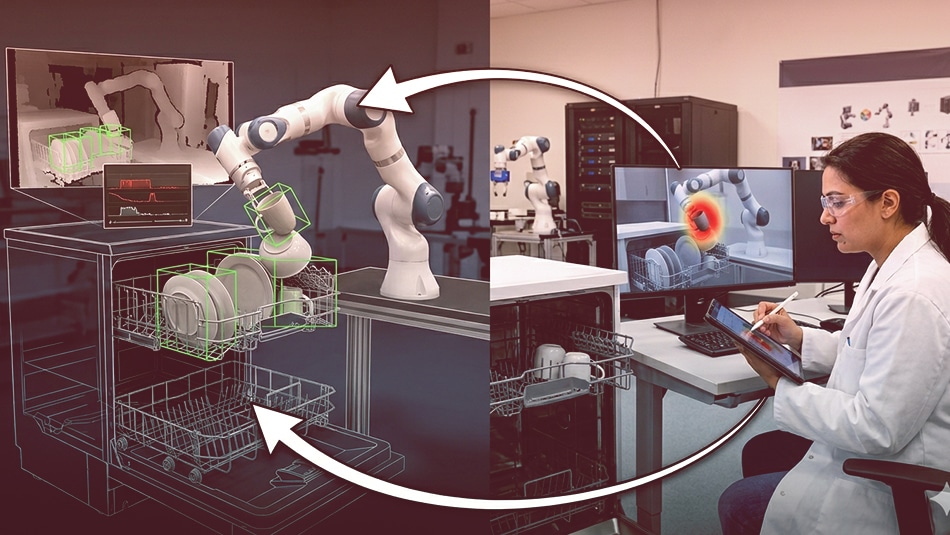
Robotics data pipelines look almost nothing like LLM data pipelines. Text annotation parallelizes cleanly across thousands of remote workers. Robotics annotation can’t. The person annotating a dishwasher-loading video needs physical intuition to recognize whether a plate placement is stable or precarious — pattern matching alone won’t catch it. Sensor variability, human unpredictability, and real-world physics introduce noise that only domain-aware annotators can resolve. Open X-Embodiment pooled over one million real-robot trajectories spanning 22 embodiments across 34 research labs (Open X-Embodiment Collaboration, 2024) — and even at that scale, human oversight remains essential for safety, edge cases, and subjective judgments about task success.
How do VLA models reshape what robot training data you need?
Vision-Language-Action (VLA) model: A foundation model that maps visual input and natural-language instructions directly to robot action commands, replacing separately trained perception, planning, and control modules.
VLA models change the data requirements in three ways. They need language annotations on every episode, not just action labels. They reward dataset diversity over raw volume — DROID delivered 76,000 trajectories across 564 scenes and 86 tasks, with diversity (not size) driving generalization gains (DROID Project, 2024). And they benefit from cross-embodiment pooling, so data captured on one robot can train policies for another. How you structure and label manipulation data now matters as much as how much you collect.
Build vs buy: when should you outsource robot training data collection?
Think of robotics training data the way semiconductor companies think about fabs. Designing your chip is core IP. Owning the fab is a different business — capital-intensive, operations-heavy, and rarely worth it unless data collection is your product. Most robotics teams should own the policy and outsource the data infrastructure.
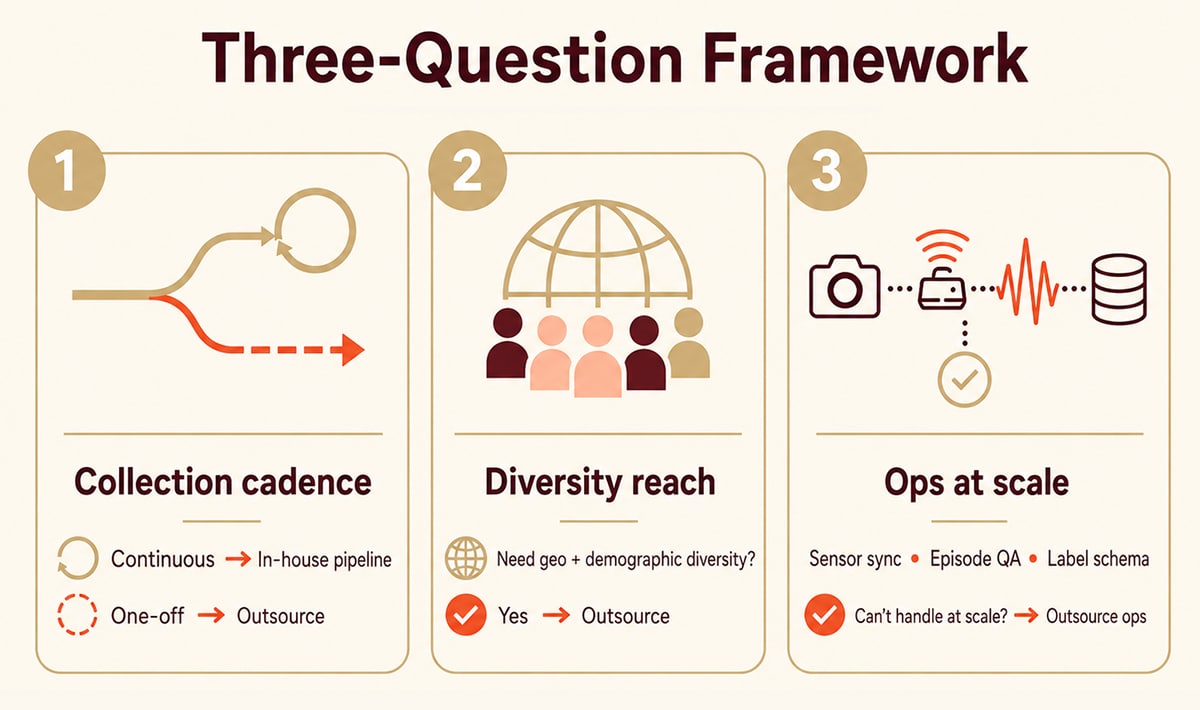
A simple three-question framework:
- Is collection one-off or continuous? Continuous = build internal pipelines; one-off = outsource.
- Do you need geographic and demographic diversity you can’t staff in-house? If yes, outsource.
- Can your team handle multimodal sensor sync, episode-level QA, and consistent label schemas at scale? If not, outsource the operations and keep the policy work in-house.
Shaip sources human demonstrators across 60+ countries, giving manipulation datasets the demographic and environmental diversity lab-only collection cannot match. Partners handling human demonstrators, real environments, and proprietary client hardware should operate under enterprise security controls — ISO 27001 for information security, SOC 2 for service-provider controls, and GDPR for human-subject demonstrations.
Conclusion
Robot training data and manipulation datasets sit at the center of every robotics deployment that actually works. The winning teams in 2026 won’t have the largest models — they’ll have the most diverse, best-structured, sensor-rich data captured under operational conditions their robots will actually face. Whether you build that pipeline internally or partner with a data specialist, the framework is consistent: combine crowdsourced diversity with onsite precision, annotate at frame, event, and task-success levels, and keep humans in the loop where physical judgment matters.









