
The Key to Overcoming AI Development Obstacles: More Reliable Data
Today, the average person now has millions of times more computing power in their pocket than NASA had to pull off the moon landing in 1969. That same ubiquitous device that conveniently demonstrates an abundance of computing power is also fulfilling another prerequisite for AI’s golden age: an abundance of data. According to insights from the Information Overload Research Group, 90% of the world’s data was created in the past two years. Now that the exponential growth in computing power has finally converged with equally meteoric growth in the generation of data, AI data innovations are exploding so much that some experts think will jump-start a Fourth Industrial Revolution.
Data from the National Venture Capital Association indicates that the AI sector saw a record $6.9 billion in investment in the first quarter of 2020. It’s not difficult to see the potential of AI tools because it’s already being tapped all around us. Some of the more visible use cases for AI products are the recommendation engines behind our favorite applications such as Spotify and Netflix. Although it’s fun to discover a new artist to listen to or a new TV show to binge-watch, these implementations are rather low-stakes. Other algorithms grade test scores — partly determining where students are accepted into college — and still others sift through candidate résumés, deciding which applicants get a particular job. Some AI tools can even have life-or-death implications, such as the AI model that screens for breast cancer (which outperforms doctors).
Despite steady growth in both real-world examples of AI development and the number of startups vying to create the next generation of transformational tools, challenges to effective development and implementation remain. In particular, AI output is only as accurate as input allows, which means quality is paramount.

Navigating Complex Compliance Demands
As if finding quality data weren’t difficult enough, some of the industries that stand to gain the most from AI data innovations are also the most heavily regulated. Healthcare is perhaps the best example, and while a survey from HIT Infrastructure found that 91% of industry insiders think the technology could improve access to care, that optimism is tempered by the fact that 75% see it as a threat to patient security and privacy — and patients aren’t the only ones at risk.
The sweeping regulations enacted through the Health Insurance Portability and Accountability Act are now intersecting with various local data compliance hurdles such as Europe’s General Data Protection Regulation, the California Consumer Privacy Act in the United States, and the Personal Data Protection Act in Singapore. These local regulations will be joined by many more, and as telehealth emerges as a more significant source of healthcare data, it’s likely that regulations will gain an even tighter grip on patient data in transit. As a result, Shaip’s secure and compliant cloud platform will prove to be an even more valuable means to amass and access healthcare data to train AI products.
Personally identifiable information can be a significant threat to your AI development, but even a completely compliant implementation is at risk if it can’t deliver the kind of accurate results that only come with diverse training data. A 2020 study in the Journal of the American Medical Association demonstrated that machine learning algorithms in the medical field are most often trained with data from patients in California, New York, and Massachusetts. Given that these patients represent less than one-fifth of the U.S. population, to say nothing of the rest of the world, it’s hard to imagine how these models could produce anything but biased results.

Overcoming AI Development Obstacles
AI development efforts include significant obstacles no matter what industry they take place in, and the process of getting from a feasible idea to a successful product is fraught with difficulty. Between the challenges of acquiring the right data and the need to anonymize it to comply with all relevant regulations, it can feel like actually constructing and training an algorithm is the easy part.
To give your organization every advantage necessary in the effort to design a groundbreaking new AI development, you’ll want to consider partnering with a company like Shaip. Chetan Parikh and Vatsal Ghiya founded Shaip to help companies engineer the kinds of solutions that could transform healthcare in the U.S. After more than 16 years in business, our company has grown to include more than 600 team members, and we’ve worked with hundreds of customers to turn compelling ideas into AI solutions.
With our people, processes, and platform working for your organization, you can immediately unlock the following four benefits and catapult your project toward a successful finish:
1. The capacity to liberate your data scientists
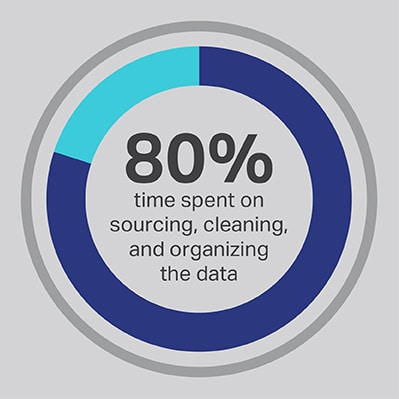
There’s no getting around that the AI development process takes a considerable investment of time, but you can always optimize the functions that your team spends the most time performing. You hired your data scientists because they’re experts in the development of advanced algorithms and machine learning models, but the research consistently demonstrates that these workers actually spend 80% of their time sourcing, cleaning, and organizing the data that will power the project. More than three-quarters (76%) of data scientists report that these mundane data collection processes also happen to be their least favorite parts of the job, but the need for quality data leaves just 20% of their time for actual development, which is the most interesting and intellectually stimulating work for many data scientists. By sourcing data through a third-party vendor such as Shaip, a company can let its expensive and talented data engineers outsource their work as data janitors and instead spend their time on the parts of AI solutions where they can produce the most value.
2. The ability to achieve better outcomes

Relying on open-source data is another common shortcut that comes with its own set of pitfalls. A lack of differentiation is one of the biggest issues, because an algorithm trained using open-source data is more easily replicated than one built on licensed data sets. By going this route, you invite competition from other entrants in the space who could undercut your prices and take market share at any time. When you rely on Shaip, you’re accessing the highest-quality data assembled by a skillful managed workforce, and we can grant you an exclusive license for a custom data set that prevents competitors from easily recreating your hard-won intellectual property.
3. Access to experienced professionals

With domain experts identifying, organizing, categorizing, and labeling data for you, you know the information used to train your algorithm can produce the best possible outcomes. We also conduct regular quality assurance to make sure that data meets the highest standards and will perform as intended not just in a lab, but also in a real-world situation.
4. An accelerated development timeline
AI development doesn’t happen overnight, but it can happen faster when you partner with Shaip. In-house data collection and annotation creates a significant operational bottleneck that holds up the rest of the development process. Working with Shaip gives you instant access to our vast library of ready-to-use data, and our experts will able to source any kind of additional inputs you need with our deep industry knowledge and global network. Without the burden of sourcing and annotation, your team can get to work on actual development right away, and our training model can help identify early inaccuracies to reduce the iterations necessary to meet accuracy goals.
If you’re not ready to outsource all aspects of your data management, Shaip also offers a cloud-based platform that helps teams produce, alter, and annotate different types of data more efficiently, including support for images, video, text, and audio. ShaipCloud includes a variety of intuitive validation and workflow tools, such as a patented solution to track and monitor workloads, a transcription tool to transcribe complex and difficult audio recordings, and a quality-control component to ensure uncompromising quality. Best of all, it’s scalable, so it can grow as the various demands of your project increase.
The age of AI innovation is only just beginning, and we’ll see incredible advancements and innovations in the coming years that have the potential to reshape entire industries or even alter society as a whole. At Shaip, we want to use our expertise to serve as a transformative force, helping the most revolutionary companies in the world harness the power of AI solutions to achieve ambitious goals.
We have deep experience in healthcare applications and conversational AI, but we also have the necessary skills to train models for almost any kind of application. For more information about how Shaip can help take your project from idea to implementation, have a look at the many resources available on our website or reach out to us today.
