
Robots can see. Internet-scale image datasets and a decade of refined models made that possible. But ask a robot to actually pick up a half-crushed carton, thread a cable, or hand a tool to a surgeon, and the wheels come off. Not because the cameras failed. Because nothing in the robot’s training ever taught it what contact is supposed to feel like. Touch is the sense Physical AI forgot, and the reason is simpler than most teams expect: the training signal doesn’t exist yet. This piece is about the signal itself — tactile sensing data. What it actually contains, how it gets produced, and what it has to be labeled with before it becomes useful. Skip any of those three questions and the models stay blind in the one sense that matters most for manipulation.
The Four Signal Classes Inside Tactile Sensing Data
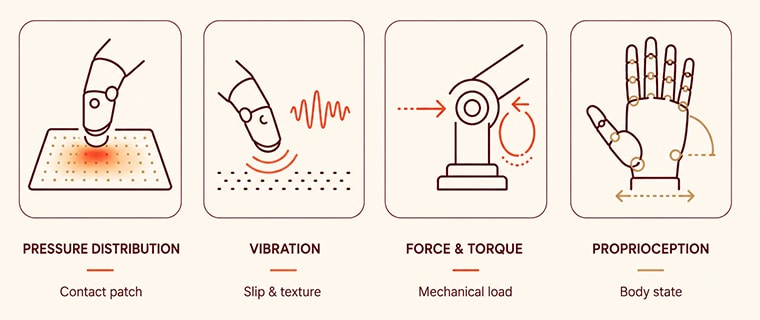
The first thing that goes wrong is that “tactile” gets treated as a single bucket. In practice, a model learning to manipulate needs four distinct signal classes, each captured by different hardware and each teaching the model something different. Pressure distribution tells the robot where and how hard contact is happening across the contact patch — enough to estimate grasp quality and object pose inside the gripper. Vibration captures high-frequency transients: the micro-events that signal slip, collision, or the rasp of a textured surface sliding against another. Force and torque describe the net mechanical exchange at the wrist or joint — the difference between pressing a button and bending it. Proprioception is the robot’s sense of its own body: finger positions, gripper aperture, joint states at the exact instant contact occurs. A model trained on any one of these in isolation is functionally one-handed.
Picture an appliance manufacturer rolling out a dual-arm cell for dishwasher wiring harness routing. Simulation got the team to a working prototype. Six weeks of teleoperated demonstrations — an experienced technician guiding the arms through hundreds of real harnesses with the full tactile stack recording — is what got it past the production floor. Teams running programs at this scale typically lean on a specialist Physical AI data collection partner to staff the operators, coordinate the rigs, and manage the cross-modal synchronization that makes the resulting data actually trainable.
One note on simulation: it’s valuable, but it can’t carry tactile on its own. Simulated contact physics still diverges meaningfully from real-world friction, deformation, and slip — especially for flexible or compliant materials. Synthetic tactile data augments a real-world dataset. It does not replace one.
What Tactile Data Needs to Be Labeled With
Raw sensor streams are not training data. They become training data only once annotators have marked what actually happened, when it happened, and how well it went. Five label families matter most.

Grasp-outcome labels: Successful, slipped, regrasped, failed — applied to every manipulation episode. These are the supervision signal for everything downstream.
Contact-regime boundaries and slip-onset timestamps: The instant the gripper touches the object. The instant the object starts to move in the grip. The instant of release. Precision here is measured in tens of milliseconds, because that’s where the learnable pattern lives.
Force magnitude brackets: Discretized force bins at each interaction phase — approach, contact, seat, hold, release. These let the model learn what a “normal” insertion force profile looks like, and therefore recognize when something is off.
Vision–tactile pairing labels: Every tactile event aligned to the visual frame that accompanies it and the proprioceptive state at that instant. Misaligned modalities teach the model confident wrong correlations, which is worse than no data.
Deformation and compliance estimates: For deformable, soft, or fragile objects, annotators capture how the object changed under the grip, and how much give the contact produced.
Labeling this well is closer to teaching someone to play an instrument by ear than to tagging photos. The annotator isn’t drawing a box around a pedestrian; they’re identifying the exact moment a pattern changed in a 1,500 Hz signal and naming what that change means. Production programs rely on purpose-built tactile and multimodal annotation workflows with staged quality control, because one sloppy annotator can quietly poison an entire training run.
Conclusion — From “Can’t Feel” to “Knows What to Feel For”
The jump from robots that can see to robots that can feel isn’t a jump in hardware. It’s a jump in the data that teaches models what touch actually means. Pressure, vibration, force, proprioception — captured in sync, collected through real interaction, and annotated with the precision the physics demands. The teams building Physical AI systems that work every shift, not just in demos, are the ones treating tactile sensing data as the training signal it is: narrow, expensive, irreplaceable, and the single layer that turns a robot from something that watches the world into something that can reliably act in it.









