
Two model classes get conflated in robotics conversations: vision-language models and vision-language-action models. They sound similar, both ingest images and text, and both come from the same lineage of multimodal pretraining. But for anyone trying to deploy an AI system that moves — not just describes — the distinction is decisive. VLM vs VLA is the difference between a model that understands a scene and a model that closes the loop with the physical world.
Key Takeaways
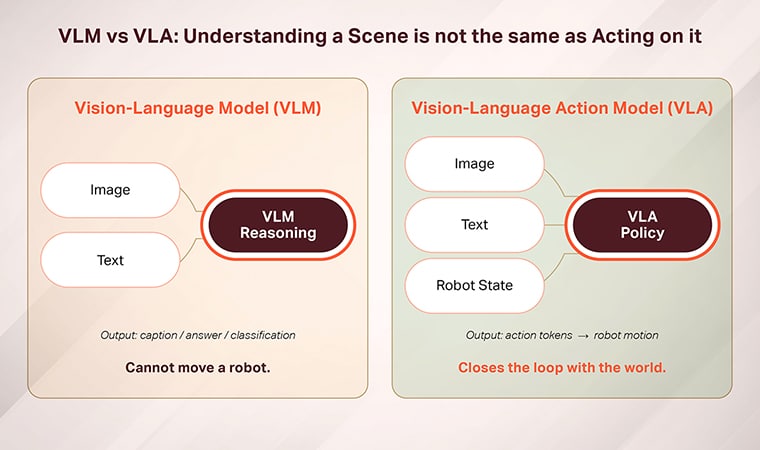
- VLMs map images and text to language outputs; VLAs map them to robot actions.
- VLMs cannot directly drive a motor, gripper, or end-effector.
- VLAs extend VLMs with action tokens trained on robot demonstration data.
- Most VLA architectures fine-tune a VLM backbone on demonstration episodes.
- Deployment-grade robotics requires VLA-style training data, not VLM data alone.
- Confusing the two leads to overestimating what a perception model can do in production.
What is a VLM?
A VLM (vision-language model) is a multimodal neural network that takes images and text as input and produces text or structured outputs. VLMs are trained on image-text pairs at massive scale and excel at captioning, visual question answering, and visual reasoning.

VLM: A multimodal model that consumes vision and language inputs and produces language or symbolic outputs, such as captions, classifications, or chains of reasoning.
VLMs are powerful — but their output space is symbolic, not physical. They can describe what’s happening in a kitchen, identify an object, or answer questions about a scene. They cannot pick anything up.
What is a VLA?
A VLA (vision-language-action) model is a multimodal model that consumes vision and language inputs and produces robot action sequences. The output space includes motor commands, end-effector poses, or action tokens that decode into continuous control signals.

VLA: A robotic foundation model that emits actions, not text — typically discretized motion tokens that map onto a robot’s degrees of freedom.
In one of the foundational papers establishing this paradigm, RT-2 fine-tuned vision-language backbones on robot demonstration data and outputted discretized action tokens (DeepMind, 2023). That output transition — from text to action — is the entire architectural difference.
How do VLM and VLA training data differ?

VLM training data and VLA training data differ in what’s at the end of each example. A VLM example pairs an image with a caption or question-answer. A VLA example pairs an image with an instruction and an action trajectory grounded in a specific robot embodiment.
A useful analogy: a VLM is like a sports analyst who can describe every play in detail but has never held a ball. A VLA is the player. The analyst’s expertise is real and useful — it just doesn’t substitute for ball-handling reps. VLA training data is those reps: synchronized observations, language instructions, action labels, and outcome markers, repeated across millions of episodes.
Why can’t you just use a VLM for robotics?
 You can’t use a VLM directly for robotics because the output token space doesn’t correspond to motor commands. A VLM outputs words; a robot needs joint angles, end-effector velocities, or gripper states. The gap between “the cup is on the left” and “move the wrist 4cm to the left and close the gripper” is the gap a VLA fills.
You can’t use a VLM directly for robotics because the output token space doesn’t correspond to motor commands. A VLM outputs words; a robot needs joint angles, end-effector velocities, or gripper states. The gap between “the cup is on the left” and “move the wrist 4cm to the left and close the gripper” is the gap a VLA fills.
In practice, many teams fine-tune VLMs into VLAs by extending the output vocabulary with action tokens — discretized motion units treated like words. This preserves the VLM’s reasoning while giving it a way to act.
Action token: A discretized robot motion encoded as a vocabulary entry that a model can predict the same way it predicts a language token.
Picture a logistics startup that licenses a high-quality VLM and assumes it can drive a pick-and-place robot. The model perceives the scene flawlessly, narrates the right plan, and produces no motor commands. Without action-token training, the system stays stuck at narration. Adding VLA data on top is what unlocks deployment.









