
The shift from chatbots to robots that follow natural-language commands runs through a single class of models. VLA models — vision-language-action models — combine visual perception, language understanding, and action generation in one neural network. Their power is real, but it depends almost entirely on the training data they ingest. This guide explains what VLA training data actually contains, what teams underestimate, and how to plan a dataset that produces a model worth deploying.
Key Takeaways
- VLA models map vision and language inputs directly to robot actions in one network.
- Training data must include synchronized visual observations, language instructions, and actions.
- Discrete action tokens require large-scale demonstration data to learn well.
- Egocentric human video is increasingly mined as a low-cost VLA pretraining source.
- Robust evaluation episodes are as important as training data for reliable deployment.
- VLA fine-tuning succeeds or fails on annotation rigor, not raw volume alone.
What is a VLA model?
A VLA model is a robotic foundation model that takes images and natural-language instructions as input and outputs robot actions. Unlike traditional pipelines that separate perception, planning, and control into different modules, vision-language-action models learn an end-to-end mapping in a single network.
VLA model: A neural network that takes synchronized visual observations and natural-language instructions and produces sequences of robot actions or action tokens.
This unified design lets VLA models inherit reasoning capabilities from large vision-language pretraining and extend them with motor control. For deployment, that means one model can in principle execute many tasks — but only if its training data covers them with the right structure.
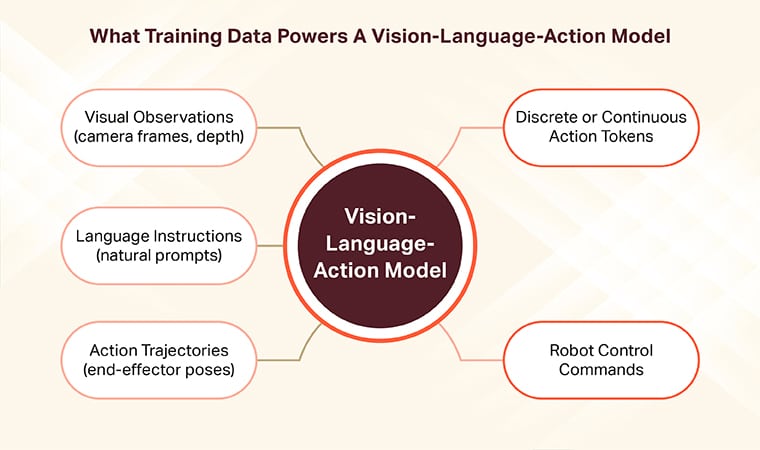
What does VLA training data actually contain?
VLA training data contains four core ingredients per episode: visual observations, a natural-language instruction, an action trajectory, and a success or failure label. Around those, teams add timestamps, proprioceptive state, and evaluation markers.

The four mandatory layers:
- Visual observations — RGB frames, often paired with depth or wrist-cam views.
- Language instructions — concise natural-language commands such as “pour water into the cup.”
- Action trajectories — discretized or continuous action sequences mapped to robot degrees of freedom.
- Outcome labels — explicit success, failure, or partial-completion markers per episode.
A 7-billion-parameter open VLA model was trained on more than one million episodes drawn from 22 robot embodiments (Stanford et al., 2024), illustrating the diversity expected for cross-task generalization. Without this breadth, VLA models tend to memorize specific objects rather than generalize.
Why is action annotation harder than image annotation?
Action annotation is harder because actions live in continuous, high-dimensional spaces and depend on robot embodiment, not just frame content. Labeling a bounding box on a cup is straightforward; labeling a trajectory that successfully grasps that cup with a specific gripper at a specific contact point is not.
Action token: A discretized representation of a robot motion or end-effector displacement that a VLA model can predict like a language token.
Annotation teams need to align each action token with its synchronized observation, mark contact instants, capture failure recovery, and tag the language instruction’s atomic boundaries. Shaip’s data annotation workflows handle this at scale, with structured taxonomies tuned to robotic action spaces and per-task acceptance thresholds.
Where does egocentric human video fit into VLA training?
 Egocentric human video fits as a scalable pretraining source that fills gaps real robot data cannot. First-person footage of humans cooking, picking, and assembling captures behaviors at a scale robot teleoperation will never reach.
Egocentric human video fits as a scalable pretraining source that fills gaps real robot data cannot. First-person footage of humans cooking, picking, and assembling captures behaviors at a scale robot teleoperation will never reach.
A recent paper transformed unstructured egocentric human videos into VLA-formatted episodes — 1 million segments and 26 million frames — by treating the human hand as a dexterous end-effector (Wu et al., arXiv, 2025). This kind of cross-embodiment data is now routine in VLA pretraining recipes.
The catch: raw video is not training data. It needs segmentation, language descriptions, hand-pose retargeting, and quality validation before it reaches a VLA pipeline. Shaip’s Physical AI data ops include egocentric capture, real2sim conversion, and VLA-aligned annotation in a single delivery.
How do you build evaluation sets that catch VLA failure modes?
Evaluation sets catch VLA failure modes when they are designed before training, not after. Three structures matter most: in-distribution success benchmarks, out-of-distribution generalization probes, and risk-tiered safety scenarios.
Imagine a household VLA model trained extensively on kitchen tasks. A reasonable evaluation set would test: known tasks in known kitchens (in-distribution), known tasks in unfamiliar lighting (mild OOD), unknown objects with known instructions (concept generalization), and rare events such as accidental spills (safety tier). Without each, deployment risk stays unmeasured.
A useful neutral resource for organizing risk-tier coverage is the NIST AI Risk Management Framework, which separates impact tiers in a way that maps cleanly onto evaluation set design.









