



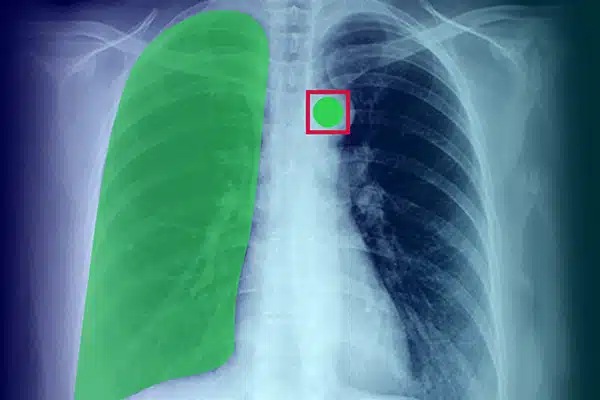
Image Annotation
Enhance medical AI by annotating visual data from X-rays, CT scans, and MRIs. Ensure AI models perform excellently in diagnostics and treatment, guided by expert data labeling. Get better patient outcomes with superior imaging insights.
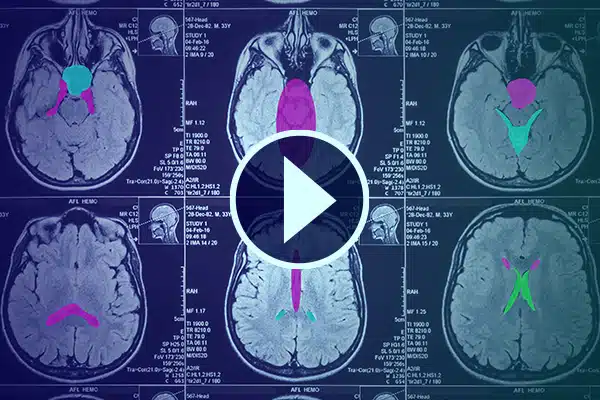
Video Annotation
Advance AI in healthcare with detailed video annotation. Sharpen AI learning with classifications and segmentations in medical footage. Improve your surgical AI and patient monitoring for improved healthcare delivery and diagnostics.
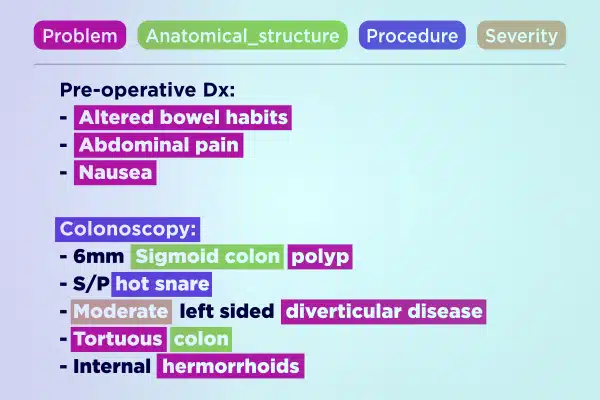
Text Annotation
Streamline medical AI development with expertly annotated text data. Quickly parse and enrich vast text volumes, from hand-written notes to insurance reports. Ensure accurate and actionable insights for healthcare advancements.

Audio Annotation
Leverage NLP expertise to annotate and label medical audio data accurately. Craft voice-assisted systems for seamless clinical operations and integrate AI into various voice-activated healthcare products. Enhance diagnostic precision with expert audio data curation.

Medical Coding
Streamline medical documentation by converting it into universal codes with AI medical coding. Ensure accuracy, enhance billing efficiency, and support seamless healthcare service delivery with cutting-edge AI assistance in medical record coding.

Phase 1: Technical domain expertise (Understand scope & annotation guidelines)

Phase 2: Training appropriate resources for the project

Phase 3: Feedback cycle and QA of the annotated documents
Radiology
Our radiology image annotation service sharpens AI diagnostics and includes an added layer of expertise. Each X-ray, MRI, and CT scan is meticulously labeled and reviewed by a subject matter expert. This extra step in training and reviewing boosts the AI's ability to spot abnormalities and diseases. It enhances accuracy before delivery to our clients.

Cardiology
Our cardiology-focused image annotation sharpens AI diagnostics. We bring in cardiology experts who label complex heart-related images and train our AI models. Before we send data to clients, these specialists review each image to ensure top-notch accuracy. This process empowers AI to detect heart conditions more precisely.
Dentistry
Our image annotation service in dentistry labels dental imagery to enhance AI diagnostic tools. By accurately identifying tooth decay, alignment issues, and other dental conditions, our SMEs empower AI to improve patient outcomes and support dentists in precise treatment planning and early detection.


















People
Dedicated and trained teams:
- 30,000+ collaborators for Data Creation, Labeling & QA
- Credentialed Project Management Team
- Experienced Product Development Team
- Talent Pool Sourcing & Onboarding Team

Process
Highest process efficiency is assured with:
- Robust 6 Sigma Stage-Gate Process
- A dedicated team of 6 Sigma black belts – Key process owners & Quality compliance
- Continuous Improvement & Feedback Loop

Platform
The patented platform offers benefits:
- Web-based end-to-end platform
- Impeccable Quality
- Faster TAT
- Seamless Delivery



