
AI, Big Data, and Machine Learning continue to influence policymakers, businesses, science, media houses, and a variety of industries throughout the world. Reports suggest that the global adoption rate of AI is currently at 35% in 2022 – a whopping 4% increase from 2021. An additional 42% of companies are reportedly exploring the many benefits of AI for their business.
Powering the many AI initiatives and Machine Learning solutions is data. AI can only be as good as the data feeding the algorithm. Low-quality data could result in low-quality outcomes and inaccurate predictions.
While there has been a lot of attention on ML and AI solution development, the awareness of what qualifies as a quality dataset is missing. In this article, we navigate the timeline of quality AI training data and identify the future of AI through an understanding of data collection and training.
Definition of AI training data
When building an ML solution, the quantity and the quality of the training dataset matter. The ML system not only requires large volumes of dynamic, unbiased, and valuable training data, but it also needs a lot of it.
But what is AI training data?
AI training data is a collection of labeled data used to train the ML algorithm to make accurate predictions. The ML system tries to recognize and identify patterns, understand relationships between parameters, make necessary decisions, and evaluate based on the training data.
Take the example of self-driving cars, for instance. The training dataset for a self-driving ML model should include labeled images and videos of cars, pedestrians, street signs, and other vehicles.
In short, to enhance the quality of the ML algorithm, you need large quantities of well-structured, annotated, and labeled training data.
Importance of quality training data and its Evolution
High-quality training data is the key input in AI and ML app development. Data is collected from various sources and presented in an unorganized form unsuitable for machine learning purposes. Quality training data – labeled, annotated, and tagged – is always in an organized format – ideal for ML training.
Quality training data makes it easier for the ML system to recognize objects and classify them according to predetermined features. The dataset could yield bad model outcomes if the classification is not accurate.
The Early Days of AI Training Data
Despite AI dominating the present business and research world, the early days before ML dominated Artificial Intelligence was quite different.
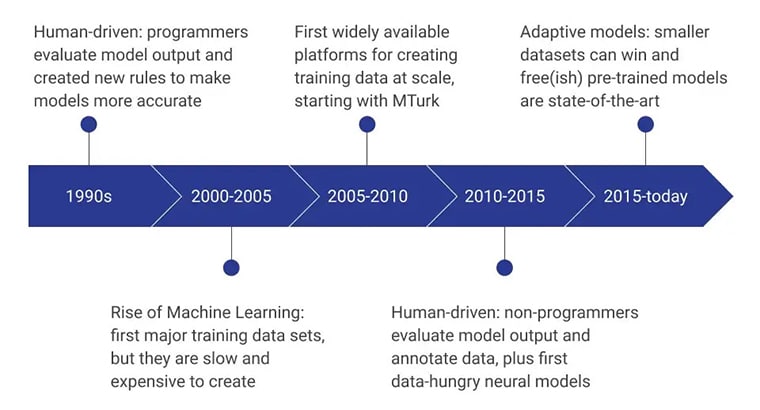 The initial stages of AI training data were powered by human programmers who evaluated the model output by consistently devising new rules that made the model more efficient. In the 2000 – 2005 period, the first major dataset was created, and it was an extremely slow, resource-reliant, and expensive process. It led to training datasets being developed at scale, and Amazon’s MTurk played a significant role in changing people’s perceptions towards data collection. Simultaneously, human labeling and annotation also took off.
The initial stages of AI training data were powered by human programmers who evaluated the model output by consistently devising new rules that made the model more efficient. In the 2000 – 2005 period, the first major dataset was created, and it was an extremely slow, resource-reliant, and expensive process. It led to training datasets being developed at scale, and Amazon’s MTurk played a significant role in changing people’s perceptions towards data collection. Simultaneously, human labeling and annotation also took off.
The next few years focussed on non-programmers creating and evaluating the data models. Currently, the focus is on pre-trained models developed using advanced training data collection methods.
Quantity over quality
When assessing the integrity of AI training datasets back in the day, data scientists focussed on AI training data quantity over quality.
For instance, there was a common misconception that large databases deliver accurate results. The sheer volume of data was believed to be a good indicator of the value of data. Quantity is only one of the primary factors determining the value of the dataset – the role of data quality was recognized.
The awareness that data quality depended on data completeness, reliability, validity, availability, and timeliness increased. Most importantly, data suitability for the project determined the quality of the data gathered.
Limitations of early AI systems due to poor training data
Poor training data, coupled with the lack of advanced computing systems, was one of the reasons for several unfulfilled promises of early AI systems.
Due to the lack of quality training data, ML solutions could not accurately identify visual patterns stalling the development of neural research. Although many researchers identified the promise of spoken language recognition, research or development of speech recognition tools could not come to fruition thanks to the lack of speech datasets. Another major obstacle to developing high-end AI tools was the computers’ lack of computational and storage capabilities.
The Shift to Quality Training Data
There was a marked shift in the awareness that the dataset’s quality matters. For the ML system to accurately mimic human intelligence and decision-making capabilities, it has to thrive on high-volume, high-quality training data.
Think of your ML data as a survey – the larger the data sample size, the better the prediction. If the sample data doesn’t include all variables, it might not recognize patterns or bring inaccurate conclusions.
Advancements in AI technology and the need for better training data
 The advancements in AI technology are increasing the need for quality training data.
The advancements in AI technology are increasing the need for quality training data.The understanding that better training data increases the chance of reliable ML models gave rise to better data collection, annotation, and labeling methodologies. The quality and relevancy of the data directly impacted the quality of the AI model.
Increased focus on data quality and accuracy
For the ML model to start providing accurate outcomes, it is fed on quality datasets that go through iterative data refining steps.
For example, a human being might be able to recognize a specific breed of dog within a few days after being introduced to the breed – through pictures, videos, or in person. Humans draw from their experience and related information to remember and pull up this knowledge when necessary. Yet, it doesn’t work as easily for a Machine. The machine has to be fed with clearly annotated and labeled images – hundreds or thousands – of that particular breed and other breeds for it to make the connection.
An AI model predicts the outcome by correlating the information trained with the information presented in the real world. The algorithm is rendered useless if the training data doesn’t include relevant information.
Importance of diverse and representative training data
 Increased data diversity also increases competence, reduces bias, and boosts equitable representation of all scenarios. If the AI model is trained using a homogenous dataset, you can be sure that the new application will work only for a specific purpose and serve a specific population.
Increased data diversity also increases competence, reduces bias, and boosts equitable representation of all scenarios. If the AI model is trained using a homogenous dataset, you can be sure that the new application will work only for a specific purpose and serve a specific population.A dataset could be biased toward a particular population, race, gender, choice, and intellectual opinions, which could lead to an inaccurate model.
It is important to ensure the entire data collection process flow, including selecting the subject pool, curation, annotation, and labeling, is adequately diverse, balanced, and representative of the population.
The Future of AI Training Data
The future success of AI models hinges on the quality and quantity of training data used to train the ML algorithms. It is critical to recognize that this relationship between data quality and quantity is task-specific and has no definite answer.
Ultimately, the adequacy of a training data set is defined by its ability to perform reliably well for the purpose it’s built.
Advances in data collection and annotation techniques
Since ML is sensitive to the fed data, it is vital to streamline data collection and annotation policies. Errors in data collection, curation, misrepresentation, incomplete measurements, inaccurate content, data duplication, and erroneous measurements contribute to insufficient data quality.
Automated data collection through data mining, web scraping, and data extraction is paving the way for faster data generation. Additionally, pre-packaged datasets act as a quick-fix data collection technique.
Crowdsourcing is another pathbreaking method of data collection. While the veracity of the data can’t be vouched for, it is an excellent tool for gathering public image. Finally, specialized data collection experts also provide data sourced for specific purposes.
Increased emphasis on ethical considerations in training data
 With the rapid advancements in AI, several ethical issues have cropped up, especially in training data collection. Some ethical considerations in training data collection include informed consent, transparency, bias, and data privacy.
With the rapid advancements in AI, several ethical issues have cropped up, especially in training data collection. Some ethical considerations in training data collection include informed consent, transparency, bias, and data privacy.Since data now includes everything from facial images, fingerprints, voice recordings, and other critical biometric data, it is becoming critically important to ensure adherence to legal and ethical practices to avoid expensive lawsuits and damage to reputation.
The potential for even better quality and diverse training data in the future
There is a huge potential for high-quality and diverse training data in the future. Thanks to the awareness of data quality and the availability of data providers who cater to the quality demands of AI solutions.
Present data providers are adept at using groundbreaking technologies to ethically and legally source massive quantities of diverse datasets. They also have in-house teams to label, annotate and present the data customized for different ML projects.
Conclusion
It is important to partner with reliable vendors with an acute understanding of data and quality to develop high-end AI models. Shaip is the premier annotation company adept at providing customized data solutions that meet your AI project needs and goals. Partner with us and explore the competencies, commitment, and collaboration we bring to the table.









