
If you only look at automated scores, most LLMs seem great—until they write something subtly wrong, risky, or off-tone. That’s the gap between what static benchmarks measure and what your users actually need. In this guide, we show how to blend human judgment (HITL) with automation so your LLM benchmarking reflects truthfulness, safety, and domain fit—not just token-level accuracy.
What LLM Benchmarking Really Measures
Automated metrics and leaderboards are fast and repeatable. Accuracy on multiple-choice tasks, BLEU/ROUGE for text similarity, and perplexity for language modeling give directional signals. But they often miss reasoning chains, factual grounding, and policy compliance—especially in high-stakes contexts. That’s why modern programs emphasize multi-metric, transparent reporting and scenario realism.
Automated metrics & static test sets
Think of classic metrics as a speedometer—great for telling you how fast you’re going on a smooth highway. But they don’t tell you if the brakes work in the rain. BLEU/ROUGE/perplexity help with comparability, but they can be gamed by memorization or surface-level match.
Where they fall short
Real users bring ambiguity, domain jargon, conflicting goals, and changing regulations. Static test sets rarely capture that. As a result, purely automated benchmarks overestimate model readiness for complex enterprise tasks. Community efforts like HELM/AIR-Bench address this by covering more dimensions (robustness, safety, disclosure) and publishing transparent, evolving suites.
The Case for Human Evaluation in LLM Benchmarks
Some qualities remain stubbornly human: tone, helpfulness, subtle correctness, cultural appropriateness, and risk. Human raters—properly trained and calibrated—are the best instruments we have for these. The trick is using them selectively and systematically, so costs stay manageable while quality stays high.
When to involve humans

- Ambiguity: instructions admit multiple plausible answers.
- High-risk: healthcare, finance, legal, safety-critical support.
- Domain nuance: industry jargon, specialized reasoning.
- Disagreement signals: automated scores conflict or vary widely.
Designing rubrics & calibration (simple example)
Start with a 1–5 scale for correctness, groundedness, and policy alignment. Provide 2–3 annotated examples per score. Run short calibration rounds: raters score a shared batch, then compare rationales to tighten consistency. Track inter-rater agreement and require adjudication for borderline cases.
Methods: From LLM-as-a-Judge to True HITL
LLM-as-a-Judge (using a model to grade another model) is useful for triage: it’s quick, cheap, and works well for straightforward checks. But it can share the same blind spots—hallucinations, spurious correlations, or “grade inflation.” Use it to prioritize cases for human review, not to replace it.
A practical hybrid pipeline
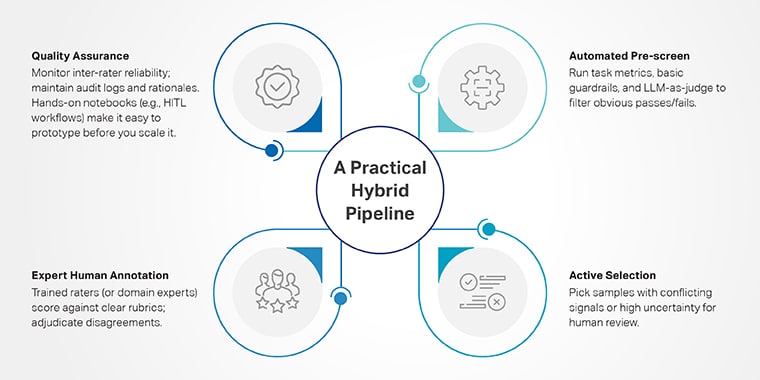
- Automated pre-screen: run task metrics, basic guardrails, and LLM-as-judge to filter obvious passes/fails.
- Active selection: pick samples with conflicting signals or high uncertainty for human review.
- Expert human annotation: trained raters (or domain experts) score against clear rubrics; adjudicate disagreements.
- Quality assurance: monitor inter-rater reliability; maintain audit logs and rationales. Hands-on notebooks (e.g., HITL workflows) make it easy to prototype this loop before you scale it.
Comparison Table: Automated vs LLM-as-Judge vs HITL
Safety & Risk Benchmarks Are Different
Regulators and standards bodies expect evaluations that document risks, test realistic scenarios, and demonstrate oversight. The NIST AI RMF (2024 GenAI Profile) provides a shared vocabulary and practices; the NIST GenAI Evaluation program is standing up domain-specific tests; and HELM/AIR-Bench spotlights multi-metric, transparent results. Use these to anchor your governance narrative.
What to collect for safety audits
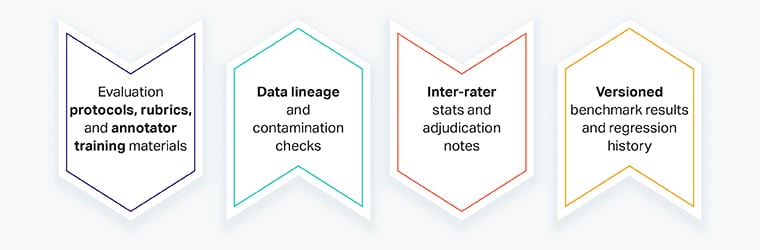
- Evaluation protocols, rubrics, and annotator training materials
- Data lineage and contamination checks
- Inter-rater stats and adjudication notes
- Versioned benchmark results and regression history

Mini-Story: Cutting False Positives in Banking KYC
A bank’s KYC analyst team tested two models for summarizing compliance alerts. Automated scores were identical. During a HITL pass, raters flagged that Model A frequently dropped negative qualifiers (“no prior sanctions”), flipping meanings. After adjudication, the bank chose Model B and updated prompts. False positives dropped 18% in a week, freeing analysts for real investigations. (The lesson: automated scores missed a subtle, high-impact error; HITL caught it.)
Where Shaip Helps
- Glossary & education: Plain-English explainer on human-in-the-loop and why it matters for GenAI.
- How-to & strategy: A beginner’s guide to LLM evaluation for teams starting from scratch.
- Platform: A Generative AI evaluation & monitoring platform to operationalize triage, experiments, and audits.









