
The Hidden Costs of “Free” Data
While open-source datasets appear cost-free, the total cost of ownership often exceeds that of commercial alternatives. Organizations must invest significant resources in data cleaning, validation, and augmentation to make open-source datasets usable. A survey by Gartner found that enterprises spend an average of 80% of their AI project time on data preparation when using open-source datasets.
Additional hidden costs include:
- Legal review and compliance verification
- Security auditing and vulnerability assessment
- Data quality improvement and standardization
- Ongoing maintenance and updates
- Risk mitigation and insurance
When factoring in these expenses, plus the potential costs of security breaches or compliance violations, professional data collection services often prove more economical in the long run.
Case Studies Highlighting the Risks
Several real-world incidents underscore the dangers of relying on open-source data:



These examples highlight the critical need for careful data selection and validation in AI development.
Strategies for Mitigating Risks
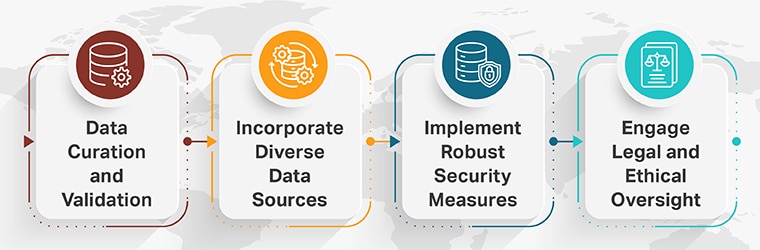
To harness the benefits of open-source data while minimizing risks, consider the following strategies:
- Data Curation and Validation: Implement rigorous data curation processes to assess the quality, relevance, and legality of datasets. Validate data sources and ensure they align with the intended use cases and ethical standards.
- Incorporate Diverse Data Sources: Augment open-source data with proprietary or curated datasets that offer greater diversity and relevance. This approach enhances model robustness and reduces bias.
- Implement Robust Security Measures: Establish security protocols to detect and mitigate potential data poisoning or other malicious activities. Regular audits and monitoring can help maintain the integrity of AI systems.
- Engage Legal and Ethical Oversight: Consult legal experts to navigate intellectual property rights and privacy laws. Establish ethical guidelines to govern data usage and AI development practices.
Building a Safer AI Data Strategy
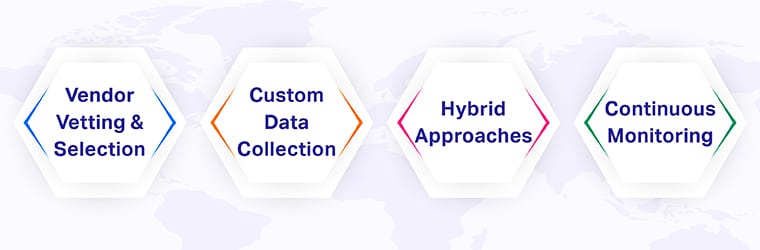
Transitioning away from risky open-source datasets requires a strategic approach that balances cost, quality, and security considerations. Successful organizations implement comprehensive data governance frameworks that prioritize:
Vendor vetting and selection: Partner with reputable data providers who maintain strict quality controls and provide clear licensing terms. Look for vendors with established track records and industry certifications.
Custom data collection: For sensitive or specialized applications, investing in custom data collection ensures complete control over quality, licensing, and security. This approach allows organizations to tailor datasets precisely to their use cases while maintaining full compliance.
Hybrid approaches: Some organizations successfully combine carefully vetted open-source datasets with proprietary data, implementing rigorous validation processes to ensure quality and security.
Continuous monitoring: Establish systems to continuously monitor data quality and model performance, enabling rapid detection and remediation of any issues.
Conclusion
While open-source data offers valuable resources for AI development, it is imperative to approach its use with caution. Recognizing the inherent risks and implementing strategies to mitigate them can lead to more ethical, accurate, and reliable AI systems. By combining open-source data with curated datasets and human oversight, organizations can build AI models that are both innovative and responsible.









