
Optical character recognition now powers receipt scanning, ID verification, invoice automation, historical archive digitization, and stylus-based note apps. The OCR market is projected to reach $32.90 billion by 2030 at a 14.8% CAGR (Grand View Research, 2024), with intelligent character recognition — the handwriting-reading branch of OCR — growing fastest. Whether you’re building document parsing, scene-text detection, or handwriting transcription, the OCR dataset you train on sets your accuracy ceiling. This guide covers 22 free, open-source OCR datasets — including the best handwriting datasets — organized by use case and refreshed with the strongest releases through 2024.
Key Takeaways
- OCR (Optical Character Recognition): technology that converts images of printed, scene, or handwritten text into machine-readable data.
- OCR datasets split into five groups: document/form, scene text, digit/character, handwriting, and multilingual.
- Document OCR datasets capture structured pages like forms and receipts; scene-text datasets capture text “in the wild.”
- IAM, MNIST, ICDAR, and SROIE remain the most-cited OCR benchmarks across research.
- License terms vary widely — verify each OCR dataset before commercial training.
What is OCR (Optical Character Recognition)?
OCR is technology that converts different types of documents, like scanned paper documents, PDFs, or images of text, into editable and searchable data. It works by:
- Analyzing the structure of text in an image
- Breaking down the text into lines and characters
- Converting these visual characters into machine-readable text
Common uses include:
- Converting scanned documents into editable text files
- Digitizing printed books
- Extracting text from photos
- Converting handwritten prescriptions to digital text
- License plate recognition
How do you choose the right OCR dataset?
Choosing an OCR dataset depends on four factors: text type, capture environment, annotation granularity, and license. Printed-document OCR needs different training data than handwritten cursive or curved scene text. Document datasets suit invoices, forms, and receipts; scene-text datasets suit signage and product reading; handwriting datasets suit notes, manuscripts, and stylus input. Word-level and line-level annotations support full OCR pipelines, while character-level sets fit classification baselines. Always confirm license terms, since some OCR datasets are research-only or require registration.
What are the best document and form OCR datasets?
Document OCR datasets train models to parse structured pages such as invoices, forms, receipts, and IDs. These power business document automation and key-value extraction.
- FUNSD — 199 annotated scanned forms with noisy, real-world appearance. The standard benchmark for form understanding and key-value extraction.
- SROIE — ICDAR 2019 scanned-receipt dataset of roughly 1,000 receipts, supporting text detection, recognition, and information extraction in a single set.
- CORD — A consolidated receipt dataset built for post-OCR parsing, with rich field-level labels for invoice and receipt automation.
- XFUND — Multilingual extension of FUNSD covering seven languages (German, Spanish, French, Italian, Japanese, Portuguese, Chinese) with 199 pages each. Ideal for multilingual document AI.
- DDI-100 — Around 100,000 distorted document images for detection and recognition under real-world degradation like skew, blur, and noise.
What are the best scene text OCR datasets?
Scene-text OCR datasets train models to read text in natural images such as signs, products, and street scenes. These are essential for in-the-wild OCR where backgrounds are cluttered.
- ICDAR Robust Reading — The benchmark family behind most scene-text research, including the Focused and Incidental Scene Text challenges with word-level bounding boxes and transcriptions.
- COCO-Text — Large-scale scene-text annotations layered on MS-COCO images. Strong for text detection at scale in natural scenes.
- Total-Text — Specializes in curved and arbitrarily oriented text, a known weak spot for older OCR models.
- SVT (Street View Text) — Word images harvested from Google Street View, often low-resolution and high-variability. Available via Papers with Code mirrors.
- HierText — Hierarchical annotation from paragraph to line to word, covering both handwritten and printed scene text. Useful for layout-aware OCR.
What are the best digit and character OCR datasets?
Digit and character OCR datasets train models to recognize individual symbols in controlled settings. These are the standard starting points for classification baselines.
- MNIST — 70,000 grayscale handwritten digit images. The fastest baseline for validating a digit classifier.
- EMNIST — Extends MNIST with 814,255 handwritten letters and digits derived from NIST Special Database 19.
- SVHN (Street View House Numbers) — Over 600,000 real-world digit images from house numbers. A practical step up from MNIST for noisy conditions.
- Chars74K — 74,107 images covering English and Kannada characters from natural images and computer fonts.
- NIST Special Database 19 — 810,000+ handprinted character images from 3,600 writers. The source many English OCR benchmarks derive from.
What are the best handwriting datasets for OCR?
Handwriting datasets train OCR models to read cursive, printed, and historical handwritten text. The strongest open handwriting datasets remain the most-cited benchmarks for handwritten text recognition (HTR).
- IAM Handwriting Database — The English handwriting gold standard, with 13,353 text lines from 657 writers. Still the most-cited handwriting dataset in 2024–2025 OCR research.
- IAM-OnDB — The online pen-stroke version of IAM, capturing trajectory data. The canonical handwriting dataset for stylus and tablet recognition.
- Bentham Papers — Transcribed historical English manuscripts from philosopher Jeremy Bentham. The leading benchmark for historical handwriting OCR, accessible via Transkribus.
- GNHK (GoodNotes Handwriting Kollection) — A 2021 dataset of unconstrained real-world English handwritten notes. Closer to messy production data than lab-clean IAM.
What are the best multilingual and non-Latin OCR datasets?
Multilingual OCR datasets train models on scripts beyond English, including Chinese, Arabic, and mathematical notation. These are essential for global document and handwriting recognition.
- CASIA-HWDB — The standard Chinese OCR benchmark, with 1.17 million handwritten character samples from 1,020 writers.
- KHATT — 1,000 Arabic handwritten forms from 1,000 distinct writers, scanned at multiple resolutions. The most comprehensive open Arabic OCR dataset.
- CROHME — Competition on Recognition of Online Handwritten Mathematical Expressions: 10,000+ expressions across 101+ math symbols, in both online and offline variants. Essential for handwritten equation OCR.
What are the common pitfalls when using free OCR datasets?
Three pitfalls catch most teams.
Domain mismatch: training on clean IAM or COCO-Text and deploying on crumpled invoices guarantees poor accuracy.
License blindness: several scene-text and historical OCR datasets are research-only or require registration before commercial use.
Annotation gaps: many OCR datasets lack the layout metadata, line-level bounding boxes, or field labels that production systems need.
Picture a mid-size logistics firm automating shipping-label reading. Public scene-text training gets them to 80% on benchmarks, but real labels with glare and folds drop them to 58%. Closing that gap required targeted data annotation of 6,000 in-domain label images before launch.
Benefits and Challenges of Open-Source Datasets
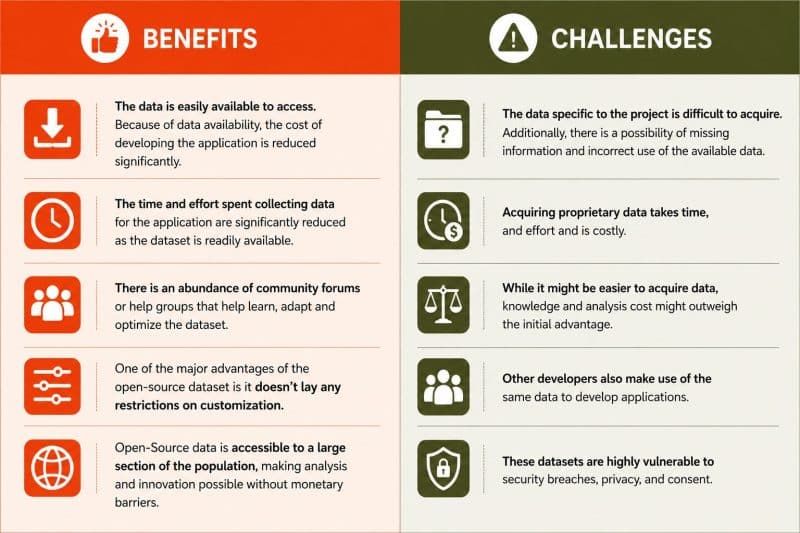
Businesses need to pit the benefits and challenges against each other to understand whether they must opt for free-to-use data for their ML applications.
Benefits
- The data is easily available to access. Because of data availability, the cost of developing the application is reduced significantly.
- The time and effort spent collecting data for the application are significantly reduced as the dataset is readily available.
- There is an abundance of community forums or help groups that help learn, adapt and optimize the dataset.
- One of the major advantages of the open-source dataset is it doesn’t lay any restrictions on customization.
- Open-Source data is accessible to a large section of the population, making analysis and innovation possible without monetary barriers.
Challenges
- The data specific to the project is difficult to acquire. Additionally, there is a possibility of missing information and incorrect use of the available data.
- Acquiring proprietary data takes time, and effort and is costly
- While it might be easier to acquire data, knowledge and analysis cost might outweigh the initial advantage.
- Other developers also make use of the same data to develop applications.
- These datasets are highly vulnerable to security breaches, privacy, and consent.
How does Shaip support OCR and handwriting recognition projects?
Shaip’s OCR training data services pair open-dataset curation with custom data collection across 60+ languages, spanning printed documents, handwriting, receipts, and IDs. Shaip’s annotation workflows add the layers public OCR datasets miss: line-level bounding boxes, field-level labels, transcription QC, and writer metadata.
Conclusion
The 22 OCR datasets above give you a complete open-source foundation across document, scene text, digit, handwriting, and multilingual recognition for 2026. Start with the OCR dataset that matches your text type and capture environment, validate against a held-out sample of your real data, and budget for custom annotation to close the domain gap. That combination ships faster than building from scratch.









