
Imagine hiring a new employee. One candidate is a “jack of all trades”—knows a little bit about everything, but not in depth. The other has 10 years of experience in your exact industry. Who do you trust with your critical business decisions?
That’s the difference between general-purpose large language models (LLMs) and domain-specific LLMs. While general models like GPT-4 or Gemini are broad and flexible, domain-focused LLMs are trained or fine-tuned for a particular field—like medicine, law, finance, or engineering.
In this post, we’ll explore what domain-specific LLMs are, highlight real-world examples, discuss how to build them, and cover both their benefits and limitations.
What Are Domain-Specific LLMs?
A domain-specific LLM is an AI model optimized to excel in a narrow, specialized area instead of general-purpose language understanding. These models are often created by fine-tuning large foundation models with carefully curated datasets from the target domain.
👉 Think of a Swiss Army knife vs. a scalpel. A general LLM can handle many tasks moderately well (like the Swiss Army knife). But a domain-specific LLM is sharp, precise, and built for specialized jobs (like the scalpel).
Examples of Domain-Specific LLMs
Domain-specialized models are already making waves across industries:
- PharmaGPT – A model focused on biopharma and drug discovery. According to recent research (arXiv:2406.18045), it demonstrates stronger accuracy on biomedical tasks while using fewer resources than GPT-4.
- DocOA – A clinical model tailored for osteoarthritis. Benchmarked in 2024 (arXiv:2401.12998), it outperformed general LLMs on specialized medical reasoning tasks.
- BloombergGPT – Built for financial markets, trained on a mix of public financial documents and proprietary datasets. It supports investment research, compliance, and risk modeling.
- Med-PaLM 2 – Developed by Google DeepMind, this healthcare-focused model achieves state-of-the-art accuracy in answering medical exam questions.
- ClimateBERT – A language model trained on climate science literature, helping researchers analyze sustainability reports and climate disclosures.
Each of these demonstrates how deep specialization can outperform general-purpose giants in targeted contexts.
Benefits of Domain-Specific LLMs
Why are enterprises rushing to build their own domain LLMs? Several key advantages stand out:
How to Build a Domain-Specific LLM
There’s no one-size-fits-all approach, but the process usually involves these key steps:
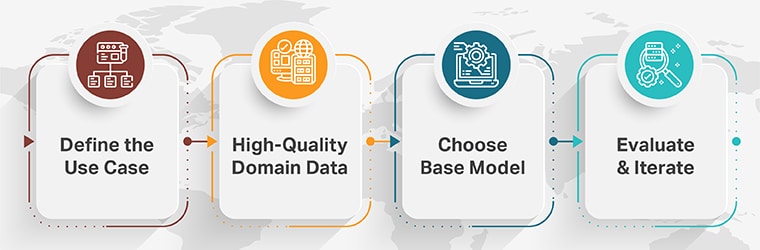
1. Define the Use Case
Identify whether the goal is customer support, compliance monitoring, drug discovery, legal analysis, or another domain-specific task.
2. Curate High-Quality Domain Data
Gather annotated datasets from your industry. Quality beats quantity here: a smaller, high-fidelity dataset often outperforms a large but noisy one.
3. Choose a Base Model
Start with a general foundation model (like LLaMA, Mistral, or GPT-4) and adapt it for the domain.
- Fine-tuning: Training on domain-specific data to adjust weights.
- Retrieval-Augmented Generation (RAG): Connecting the model to a knowledge base for real-time grounding.
- Small LLMs (SLMs): Training compact models that are efficient but highly specialized.
4. Evaluate & Iterate
Benchmark against general-purpose LLMs to ensure gains in accuracy. Track hallucination rates, latency, and compliance metrics.
Domain-Specific vs General-Purpose LLMs
How do domain-specialized models stack up against their general-purpose counterparts? Let’s compare:









