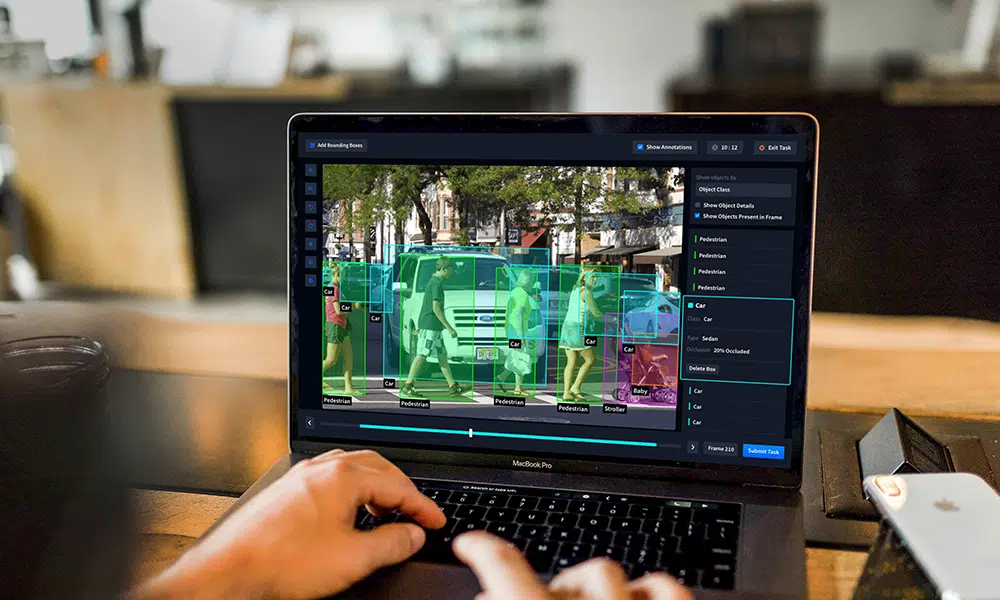
Why Multimodal Data Labeling Matters
The significance of multimodal data labeling extends far beyond technical requirements. According to recent industry research, models trained on properly labeled multimodal data demonstrate up to 40% better performance in real-world applications compared to single-modality models. This improvement translates directly into more accurate medical diagnoses, safer autonomous vehicles, and more natural human-AI interactions.
Consider a patient diagnosis system: a unimodal model analyzing only text records might miss critical visual indicators from X-rays or subtle audio cues from heart examinations. By incorporating multimodal training data, AI systems can synthesize information from patient records, medical imaging, audio recordings from stethoscopes, and sensor data from wearables—creating a comprehensive health assessment that mirrors how human doctors evaluate patients.
[Also Read: Multimodal AI: The Complete Guide to Training Data and Business Applications]
Tools and Technologies for Effective Labeling
The evolution from manual to automated multimodal data labeling has transformed the AI development landscape. While early annotation efforts relied entirely on human labelers working with basic tools, today’s platforms leverage machine learning to accelerate and enhance the labeling process.
Leading Annotation Platforms
Modern annotation platforms like provide unified environments for handling diverse data types. These tools support:
- Integrated workflows for text, image, audio, and video annotation
- Quality control mechanisms to ensure labeling accuracy
- Collaboration features for distributed teams
- API integrations with existing ML pipelines
Shaip’s data annotation services exemplifies this evolution, offering customizable workflows that adapt to specific project requirements while maintaining stringent quality standards through multi-level validation processes.
Automation and AI-Assisted Labeling
The integration of AI into the labeling process itself has created a powerful feedback loop. Pre-trained models suggest initial labels, which human experts then verify and refine. This semi-automated approach reduces labeling time by up to 70% while maintaining the accuracy essential for training robust multimodal models.

The Multimodal Data Labeling Process
Successfully labeling multimodal data requires a systematic approach that addresses the unique challenges of each data type while maintaining cross-modal consistency.

Step 1: Project Scope Definition

Begin by clearly identifying which modalities your AI model needs and how they’ll interact. Define success metrics and establish quality benchmarks for each data type.
Step 2: Data Collection and Preparation
Gather diverse datasets representing all required modalities. Ensure temporal alignment for synchronized data (like video with audio) and maintain consistent formatting across sources.
Step 3: Annotation Strategy Development
Create detailed guidelines for each modality:
Images: Bounding boxes, segmentation masks, keypoint annotations
Text: Entity recognition, sentiment tags, intent classification
Audio: Transcription, speaker diarization, emotion labeling
Video: Frame-by-frame annotation, action recognition, object tracking
Step 4: Cross-Modal Relationship Mapping
The critical differentiator in multimodal labeling is establishing connections between modalities. This might involve linking text descriptions to specific image regions or synchronizing audio transcripts with video timestamps.
Step 5: Quality Assurance and Validation
Implement multi-tier review processes where different annotators verify each other’s work. Use inter-annotator agreement metrics to ensure consistency across your dataset.
Real-World Applications Transforming Industries
Autonomous Vehicle Development
 Self-driving cars represent perhaps the most complex multimodal challenge. These systems must simultaneously process:
Self-driving cars represent perhaps the most complex multimodal challenge. These systems must simultaneously process:
- Visual data from multiple cameras
- LIDAR point clouds for 3D mapping
- Radar signals for object detection
- GPS coordinates for navigation
- Audio sensors for emergency vehicle detection
Accurate multimodal labeling of this data enables vehicles to make split-second decisions in complex traffic scenarios, potentially saving thousands of lives annually.
Healthcare AI Revolution
 Healthcare AI solutions increasingly rely on multimodal data to improve patient outcomes. A comprehensive diagnostic AI might analyze:
Healthcare AI solutions increasingly rely on multimodal data to improve patient outcomes. A comprehensive diagnostic AI might analyze:
- Electronic health records (text)
- Medical imaging (visual)
- Physician dictation notes (audio)
- Vital signs from monitoring devices (sensor data)
This holistic approach enables earlier disease detection and more personalized treatment plans.
Next-Generation Virtual Assistants
 Modern conversational AI goes beyond simple text responses. Multimodal virtual assistants can:
Modern conversational AI goes beyond simple text responses. Multimodal virtual assistants can:
- Understand spoken queries with visual context
- Generate responses combining text, images, and voice
- Interpret user emotions through voice tone and facial expressions
- Provide contextually relevant visual aids during explanations