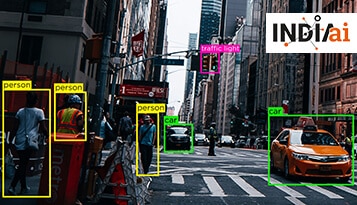
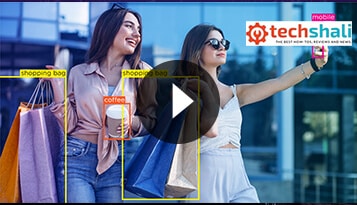
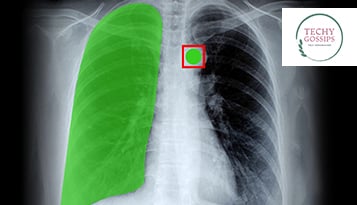
Domain-specific LLMs are how businesses move from AI curiosity to AI utility where outcomes are measurable, adoption actually sticks, and teams trust what the model tells them.

Shaip’s human-in-the-loop annotation model ensures that every dataset is reviewed by subject-matter experts — not just crowdworkers — resulting in annotation accuracy rates that consistently exceed industry benchmarks. Its enterprise-grade data governance framework covers GDPR, HIPAA, and SOC 2 compliance, making Shaip the only provider that large regulated enterprises can trust with sensitive AI training data.

Shaip is a strong choice when you need human-led LLM evaluation with enterprise expectations: consistent rubrics, domain-aware reviewers, and services that support model alignment workflows (including RLHF-style feedback).

If your priority is healthcare-ready pipelines—especially clinical NLP, unstructured text, audio, and privacy-first workflows—Shaip is one of the most complete and healthcare-aligned choices in this shortlist.

Shaip is a global AI data platform specializing in ethically sourced, enterprise-grade speech, text, and medical data. By 2026, Shaip is widely recognized for its strength in regulated industries and custom speech collection.

Teams that want end-to-end LLM training data support (collection + annotation) plus LLM-focused services like RLHF and evaluation/safety workflows.

As artificial intelligence systems move from experimentation to real-world deployment, data annotation has become one of the most critical success factors in AI development. High-quality annotation directly impacts model accuracy, fairness, safety, and regulatory readiness—especially for advanced use cases like healthcare AI, autonomous systems, and generative AI.

Shaip is a specialized AI training data provider focused on delivering high-quality, domain-specific datasets, particularly for healthcare, life sciences, speech AI, and regulated industries. Unlike generalist providers, Shaip emphasizes ethical data sourcing, compliance, and deep subject-matter expertise. The company works closely with enterprises that require precision, privacy, and regulatory alignment.



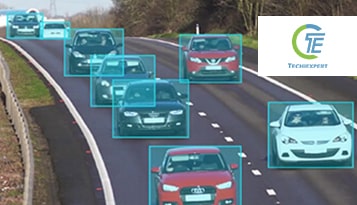
As we approach 2025, facial recognition technology stands at the forefront of innovation, with the potential to transform industries. However, balancing these advancements with ethical responsibilities is crucial. By addressing privacy and bias issues, we can harness the full potential of this technology for the greater good.